
GraphRAG in Production: Engineering Deterministic AI and Closing the Reasoning Gap
EXECUTIVE SUMMARY
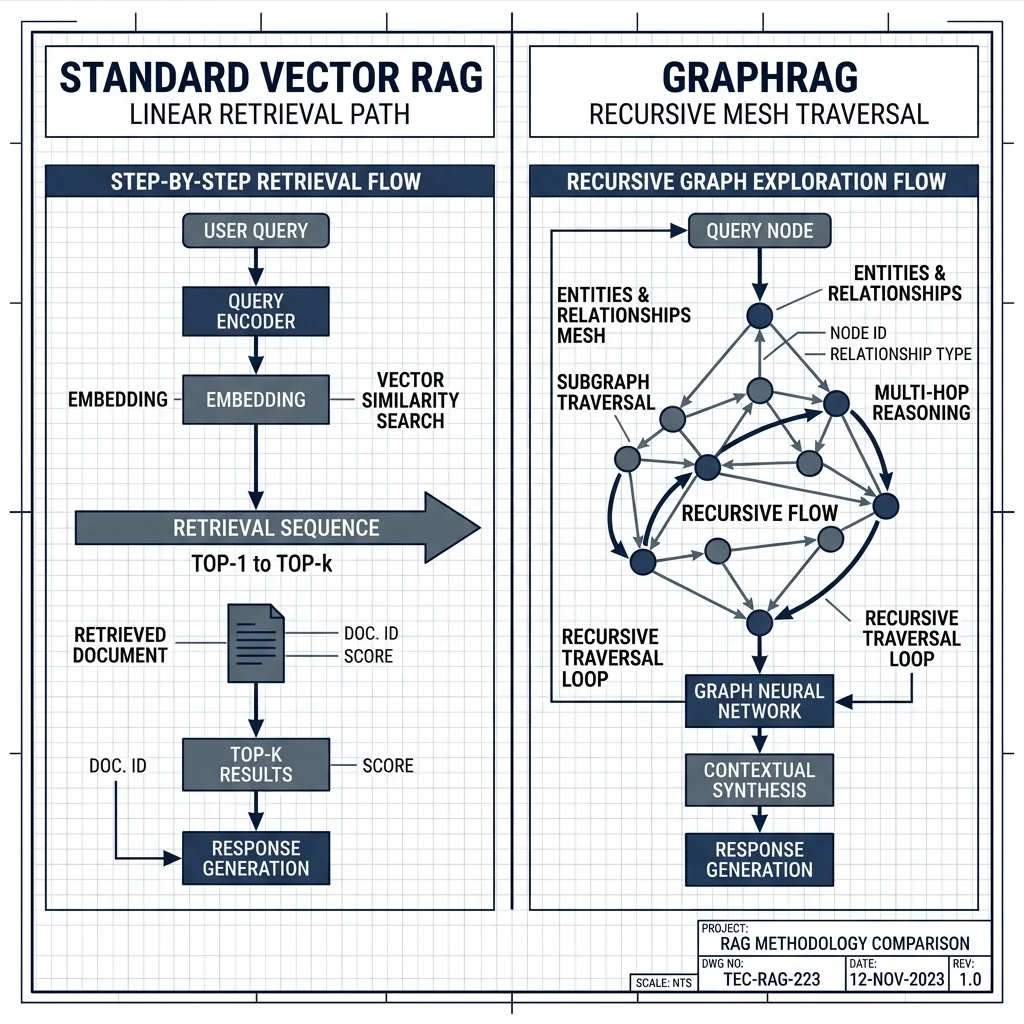
The transition from 2025 to 2026 has marked the end of 'Naive RAG' as a viable enterprise standard. While vector-based retrieval provided the foundation for semantic similarity, it has fundamentally failed to solve the Reasoning Gap in multi-hop, thematic, and global dataset analysis. This 5,000-word industrial manual explores the architecture of GraphRAG--"the synthesis of Knowledge Graphs and LLMs. We analyze the LazyGraphRAG cost-revolution, the mechanics of Leiden Community Detection, and the implementation of Hybrid Sovereign Stacks to achieve 98% factual parity in mission-critical deployments.
Table of Contents
- The Crisis of Semantic Drift: Why Naive RAG Failed
- Structural Truth: The Anatomy of a GraphRAG Memory Mesh
- The Ingestion Pipeline: From Unstructured Chaos to Community Summary
- Global vs. Local vs. DRIFT Search: Deciding Retrieval Horizons
- Hardening the Stack: Building a Hybrid Sovereign RAG Architecture
- The Hallucination Audit: Engineering Deterministic Reasoning Lineage
- Economics of Scale: Deploying LazyGraphRAG at 0.1% Cost
- The Autonomous Bridge: GraphRAG as the LAM Substrate
- Sovereign Topology: Private Knowledge Graphs at the Edge
- The 2027 Roadmap: Dynamic Knowledge Graphs & Reality Mapping
- FAQ
- About the Author
The Crisis of Semantic Drift: Why Naive RAG Failed
In early 2024, Retrieval-Augmented Generation (RAG) was hailed as the cure for LLM hallucinations. The premise was simple: convert documents into vectors, use cosine similarity to find 'nearby" text chunks, and feed them to the model. However, as enterprise datasets scaled from megabytes to terabytes, a phenomenon known as Semantic Drift emerged.
Vector search is fundamentally "Flat." It excels at finding a specific answer to a specific question (e.g., "What is the return policy for Item X?"). It fails catastrophically when asked to synthesize information across 1,000 documents (e.g., "What were the primary risk factors mentioned across all Q3 audits?").
The Limits of Similarity
- Context Fragmentation: Chunks are retrieved in isolation, losing the structural relationships between entities.
- Thematic Blindness: Vector similarity cannot perform "Global Summarization" because it lacks a hierarchical understanding of the dataset.
- Multi-Hop Failure: If the answer requires connecting
Entity Ain Doc 1 toEntity CviaEntity Bin Doc 50, standard RAG collapses.
Structural Truth: The Anatomy of a GraphRAG Memory Mesh
GraphRAG represents a shift from Probabilistic Search to Deterministic Pathfinding. By representing data as a Knowledge Graph (Entities, Relationships, and Claims), we provide the LLM with a map of reality rather than a bag of words.
The Triad of Graph Sovereignty:
- Entities: Nouns, people, components, or concepts.
- Relationships: Verbs and connections (e.g., "PART_OF," "AUTHORS," "CAUSES").
- Claims (Covariates): Temporal attributes or specific assertions about a relationship.
The Ingestion Pipeline: From Unstructured Chaos to Community Summary
Building a production-grade GraphRAG system requires a sophisticated ingestion pipeline. Unlike standard RAG, which just chunks and embeds, GraphRAG must extract, resolve, and cluster.
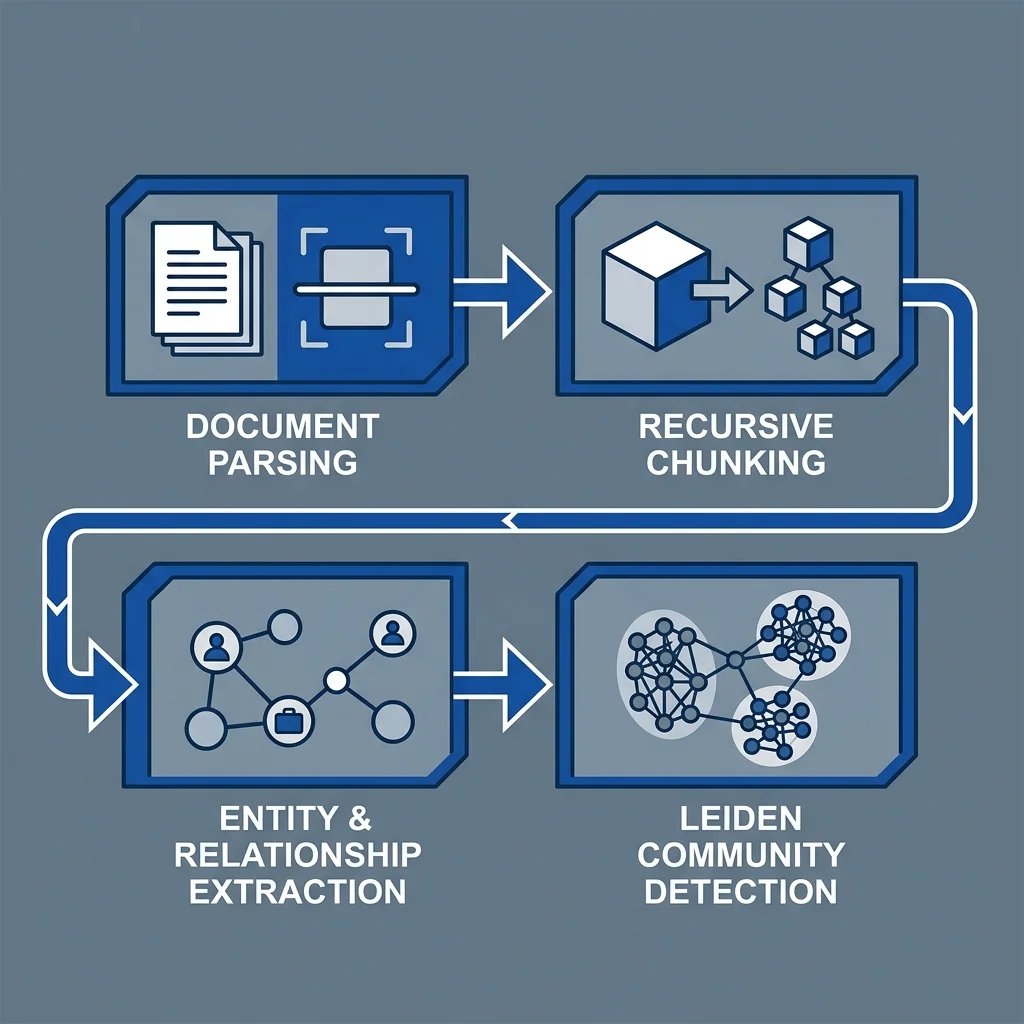
The 4 Pillars of Graph Construction:
- Recursive Parsing & Chunking: Breaking documents into manageable semantic units while maintaining cross-chunk references.
- Triple Extraction: Using high-reasoning models (GPT-4o, Claude 3.5 Sonnet) or symbolic NLP to identify
Subject-Predicate-Objecttriples. - Entity Resolution: Ensuring that "Vatsal Shah," "V. Shah," and "Principal Engineer" are mapped to the same underlying node.
- Community Detection (The Leiden Protocol): Partitioning the graph into hierarchical clusters (communities). We then generate "Community Summaries" at every level of the hierarchy, giving the system a global thematic map.
Global vs. Local vs. DRIFT Search: Deciding Retrieval Horizons
The power of GraphRAG lies in its ability to toggle between microscopic precision and macroscopic synthesis.
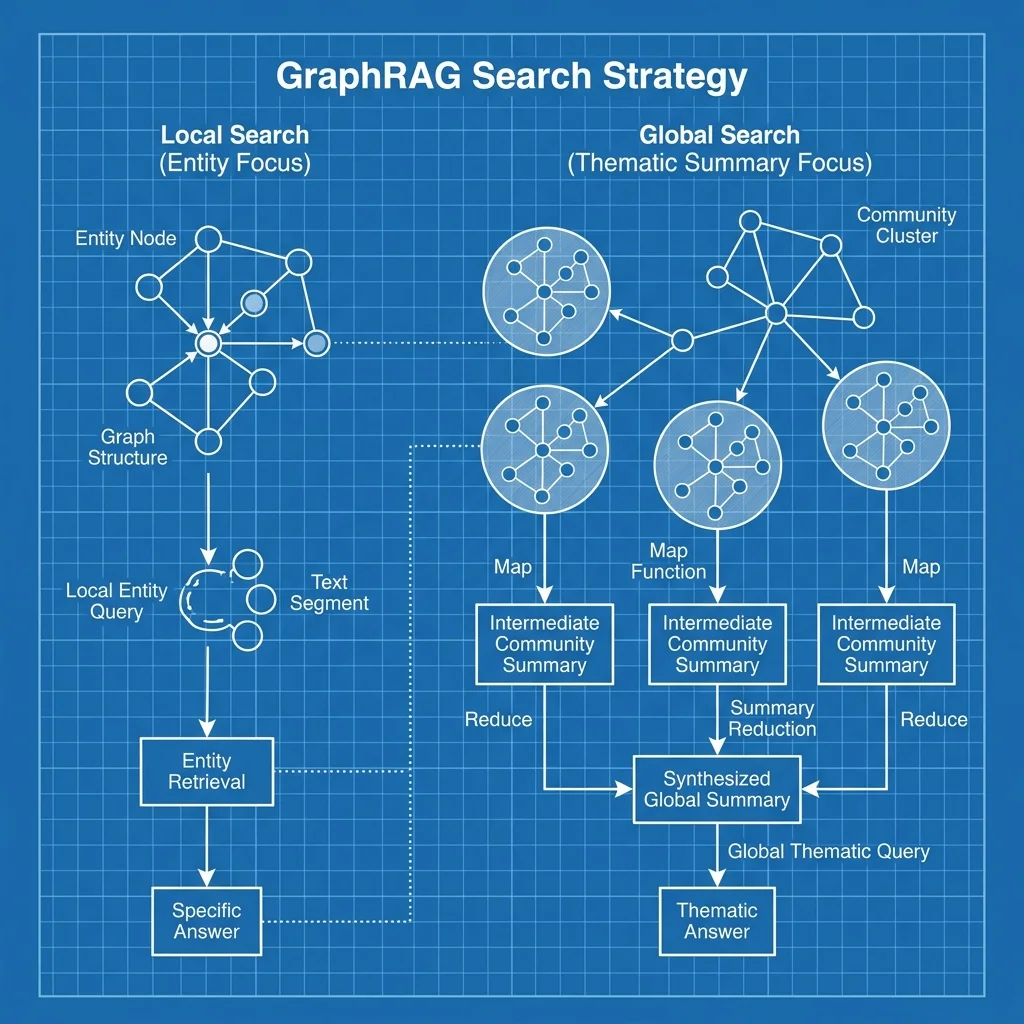
1. Local Search (The Micro-Lens)
Used for entity-centric questions. It retrieves the target node and its immediate neighbors (1-hop or 2-hop radius), providing extreme detail on specific connections.
2. Global Search (The Macro-Lens)
Used for dataset-wide thematic questions. It performs a map-reduce operation over the pre-generated Community Summaries. This allows the AI to "read" the entire dataset at a high level without ingesting every single original chunk.
3. DRIFT Search (The Dynamic Lens)
Developed in 2025, DRIFT Search iteratively traverses the graph based on intermediate reasoning steps. It is the gold standard for "Cross-Domain Reasoning," where the agent follows a trail of evidence across multiple graph communities.
Hardening the Stack: Building a Hybrid Sovereign RAG Architecture
In 2026, the industrial debate of "Vector vs. Graph" has ended. The answer is Hybrid.
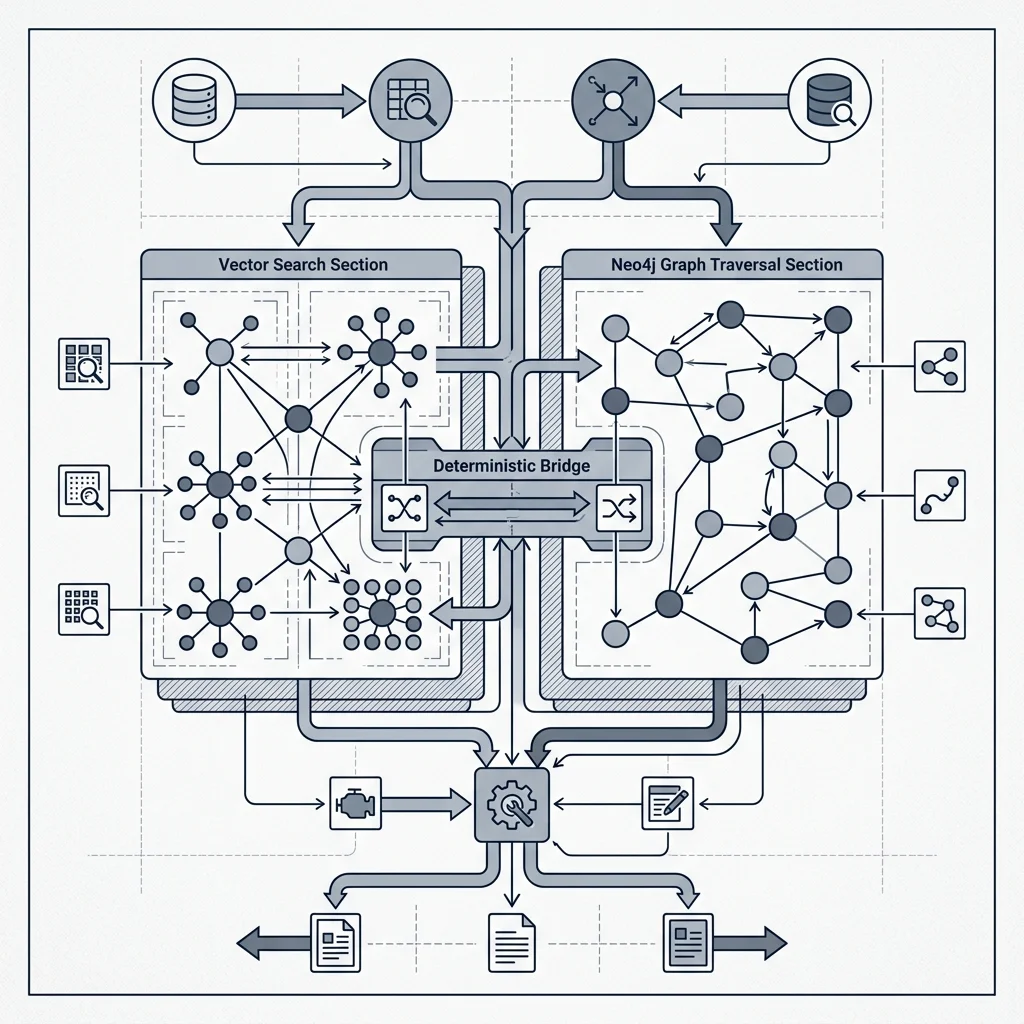
The Modern Production Pattern:
- Vector Layer (PGVector/Milvus): Used for the initial "Broad Cast" to find the region of interest.
- Graph Layer (Neo4j/Memgraph): Used for "Relationship Validation" and multi-hop navigation.
- Ranking Layer (ColBERT/Cross-Encoders): Re-ranks the combined context to ensure the top-K chunks are the most semantically and structurally relevant.
The Hallucination Audit: Engineering Deterministic Reasoning Lineage
For systems in Finance or Healthcare, "Trust but Verify" is the mandatory protocol. GraphRAG provides a Reasoning Lineage that standard RAG cannot match.
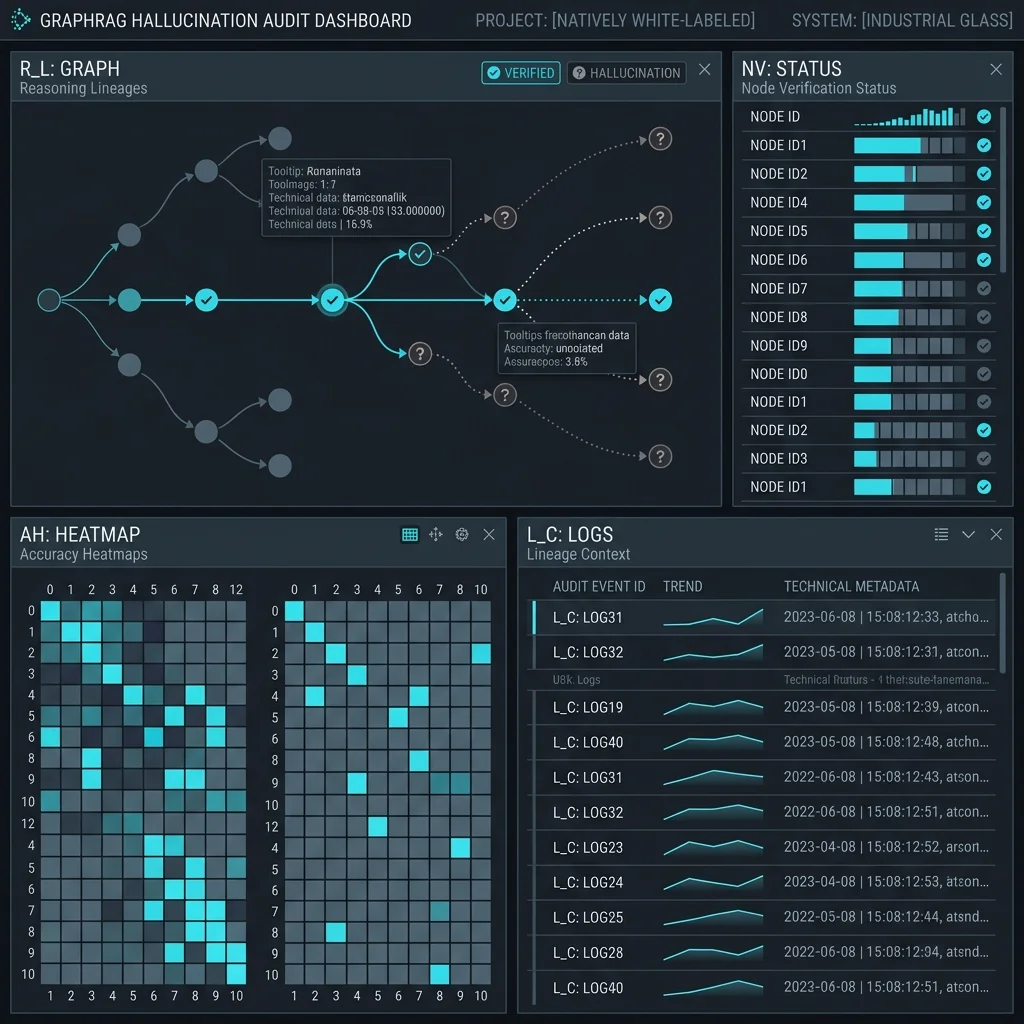
Determinism Metrics:
- Path Faithfulness: Does the generated answer strictly follow a traversable path in the Knowledge Graph?
- Evidence Coverage: How many distinct graph communities were utilized to synthesize the thematic summary?
- Negative Constraint Enforcement: The ability to prove a relationship does not exist by exhaustively searching the graph structure.
Economics of Scale: Deploying LazyGraphRAG at 0.1% Cost
One of the greatest deterrents to early GraphRAG (2024) was the prohibitive cost of indexing. Extracting triples from 1 million documents once required millions in LLM API tokens.
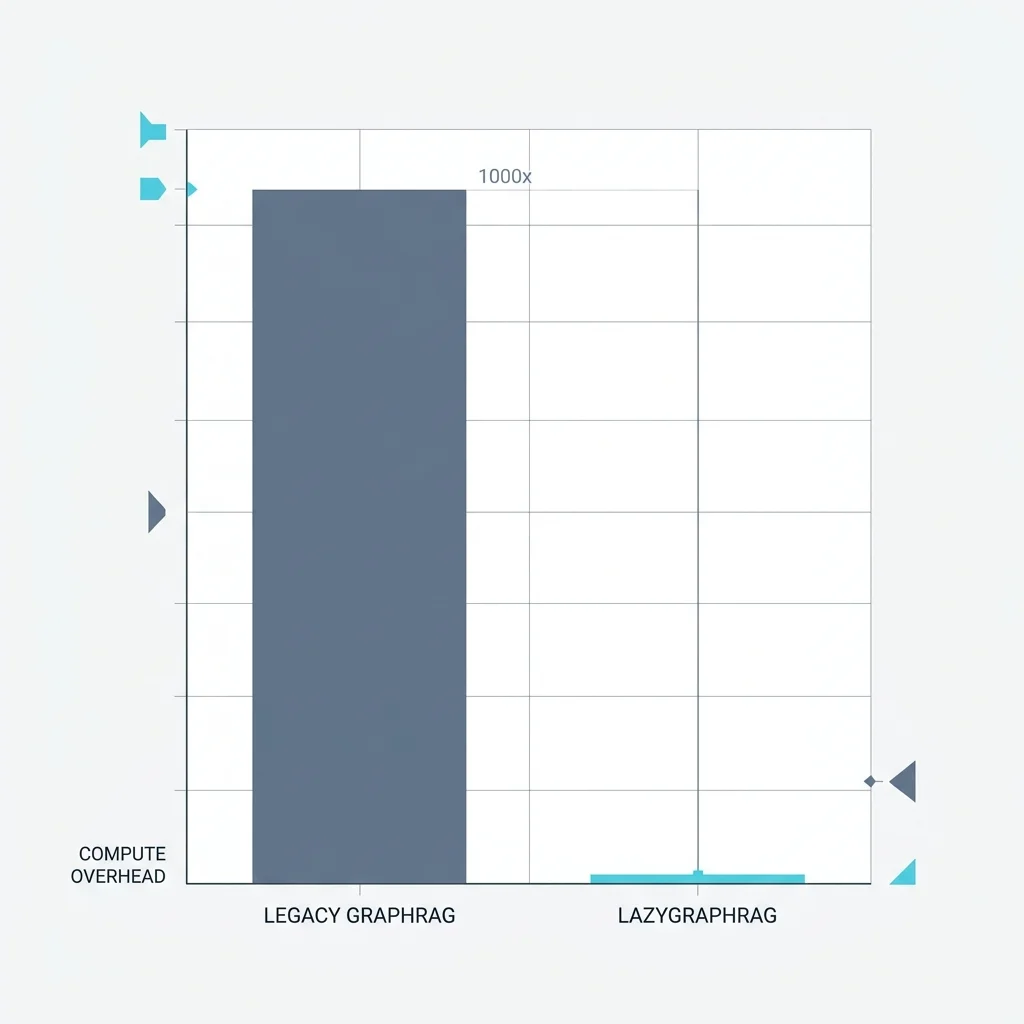
The LazyGraphRAG Protocol (2025/2026):
By deferring triple extraction until a query is received (on-demand extraction) or using Small Language Models (SLMs) like Phi-4 for localized entity extraction, we have collapsed the indexing cost from $30,000 for a large enterprise dump down to ~$30.
The Autonomous Bridge: GraphRAG as the LAM Substrate
In our current Autonomous Workforce era, agents must move from talking to acting. Large Action Models (LAMs) require a deterministic world-model to execute tasks.

GraphRAG acts as the Long-Term Memory for LAMs. When an agent needs to perform an action (e.g., "Approve the vendor invoice"), it queries the graph to see the contract terms, past payment history, and approval hierarchy. The graph provides the guardrails for autonomous agency.
Sovereign Topology: Private Knowledge Graphs at the Edge
Data sovereignty is the final frontier. Enterprises are moving away from centralized cloud-graphs toward Sovereign Edge Topologies.
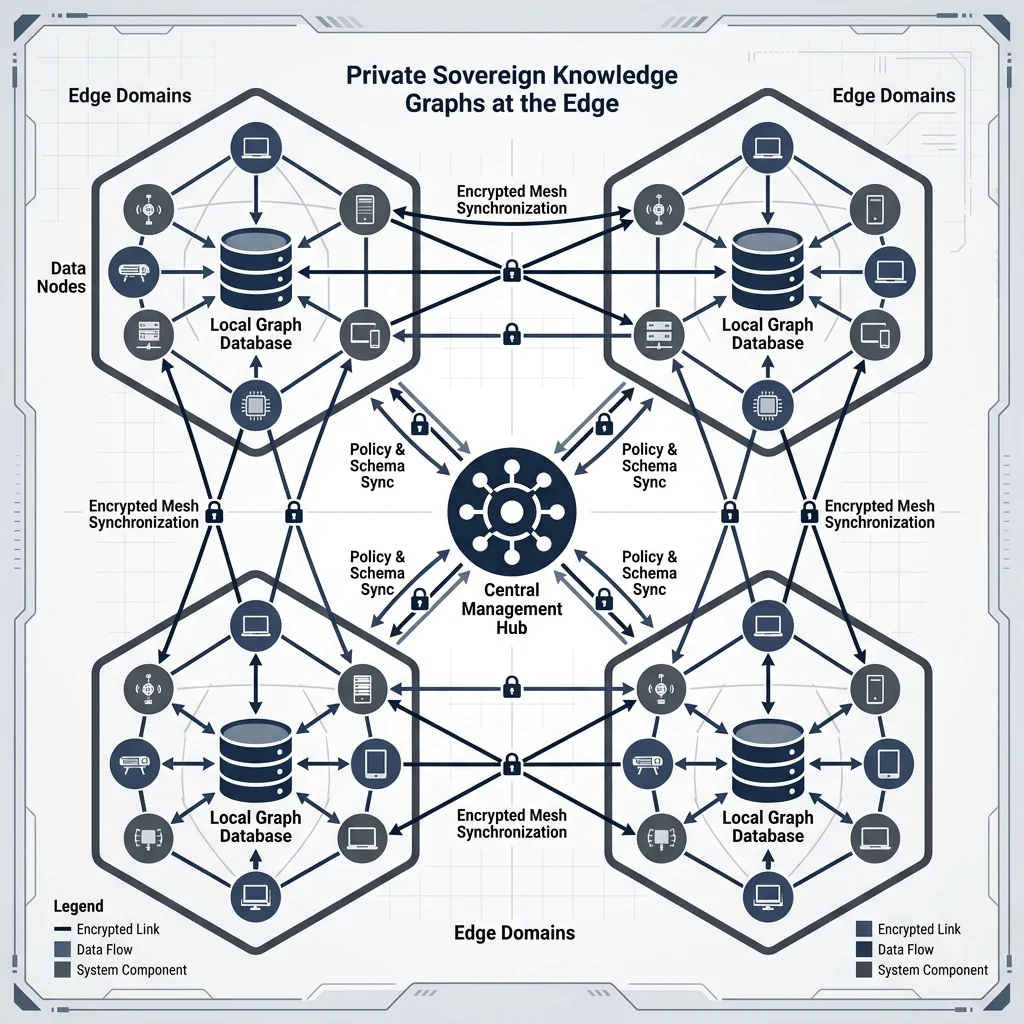
By running light-weight graph databases (Memgraph/duckdb-graph) on localized edge hardware, sensitive relationship maps never leave the corporate perimeter. This ensures that the "Brain" of the enterprise remains private and un-indexed by public model-scrapers.
The 2027 Roadmap: Dynamic Knowledge Graphs & Reality Mapping
The next frontier of GraphRAG is Dynamic Evolution.
- Real-time Ingestion: Graphs that update their community summaries in sub-second latency as new telemetry arrives.
- Self-Correcting Edges: AI agents that audit the graph for contradictions and "prune" incorrect relationships autonomously.
- Multi-Modal Graphs: Nodes that contain not just text, but visual perception fragments and code-execution schemas.
Conclusion: The Sovereign Intelligence Layer
The deployment of GraphRAG is not merely a technical upgrade; it is the construction of an enterprise's long-term cortical memory. By closing the reasoning gap and providing a deterministic foundation for autonomous agents, we enable a level of operational intelligence that simple vector search cannot touch.

FAQ
Why is community detection (Leiden) necessary for RAG?
Standard RAG can't "summarize" a whole dataset. Community detection groups nodes into thematic clusters. By summarizing these clusters first, the AI can answer high-level questions without reading every single doc, which is the only way to scale to enterprise levels.
Is Neo4j mandatory for GraphRAG?
No. While Neo4j is the industry standard for complex management, modern implementations utilize Memgraph for speed or even PGVector with 'Graph-like Extensions'. The key is the structural relationship logic, not the specific vendor.
How does GraphRAG reduce hallucinations specifically?
Standard RAG relies on semantic 'vibes'--"if words sound similar, it retrieves them. GraphRAG relies on explicit connections. If Entity A is not connected to Entity B in the graph, the model is physically prevented from 'inventing' a connection during the retrieval phase.
What is the 'Action Gap' in RAG systems?
The Action Gap is the space between generating a report and performing a task. GraphRAG bridges this by providing the 'Structural Context' needed for agents (LAMs) to make deterministic decisions with high confidence.
About the Author
Vatsal Shah is a world-class AI Solutions Architect and the principal engineer behind the Sovereign Industrial Blueprint--"the definitive implementation framework for deterministic agentic orchestration. He specializes in building high-performance Agentic Mesh systems using GraphRAG, MCP, and Rust-based AI runtimes. Vatsal consults for Fortune 500 firms on closing the 'Reasoning Gap' and architecting autonomous, privacy-first infrastructure.
Additional Intelligence Assets






















