What Happened At the Shoreline Amphitheatre in Mountain View, Google I/O 2026 kicked off with a paradigm-shifting keynote focused."
-
q: "Who should act on this first?"
a: "CTOs, platform leads, and compliance owners should review vendor exposure within one sprint — especially if AI agents touch customer data or financial workflows."
-
q: "What is the recommended next step?"
a: "Run a 30-minute architecture review: map affected systems, assign an owner, and document one measurable mitigation before the next release train."
Google I/O 2026: Gemini 2.5 Ultra and the Local Android Agent Bus Unleashed
By Vatsal Shah · May 24, 2026 · AI / Google · Source: Google Blog
- Local Sovereignty: Gemini 2.5 Ultra shifts agentic inference from cloud server Farms directly onto the mobile device's physical NPU.
- Android Agent Bus: A new OS-level IPC bus allows installed applications to register tool endpoints, making apps natively callable by the local model.
- Microsecond Latency: Bypassing cloud roundtrips reduces tool-calling latency from 1.2 seconds down to less than 15 milliseconds.
- Hardware-Level Sandboxing: Privacy is enforced by the Private Compute Core (PCC), guaranteeing zero network data egress during execution.
What Happened
At the Shoreline Amphitheatre in Mountain View, Google I/O 2026 kicked off with a paradigm-shifting keynote focused entirely on local autonomy. The headline announcement was the dual release of Gemini 2.5 Ultra (Local Edition) and the Android Agent Bus (AAB). Together, these technologies move the agentic computing revolution from remote clouds straight into the consumer's palm.
Gemini 2.5 Ultra is a highly optimized Edge model capable of run-time inference on modern mobile hardware, delivering 150 tokens per second locally. The model is specifically tuned for function calling, structured schema output, and low-bit quantization. It runs on the device’s Neural Processing Unit (NPU), requiring no external server connectivity to perform complex multi-step reasoning.
To support this local model, Google introduced the Android Agent Bus. Built directly into the Android System Server, the AAB acts as a secure, local-first message broker that lets apps register functional capability intents. Gemini 2.5 Ultra can then orchestrate complex workflows across multiple local apps without sending user data over the internet.
During the keynote, Google's VP of Android Engineering demonstrated a live, voice-activated agent workflow. The agent was asked to scan incoming receipts from the local filesystem, extract the total amounts, check the local banking app for recent transactions, and draft an expense report in Google Sheets—all while the device was completely in Airplane Mode. The entire task completed in less than 3 seconds, showcasing a massive leap over current cloud-dependent orchestrations.
The developer audience reacted with high enthusiasm. For years, mobile developers have struggled with the trade-offs of embedding AI: either pay massive cloud server costs and accept latency penalties, or run small, dumb models locally. Gemini 2.5 Ultra represents a middle path, delivering high-tier reasoning directly on consumer hardware.
The Architecture of the Local Android Agent Bus
The core innovation that enables on-device agentic loops is the OS-level integration of the Android Agent Bus. Traditionally, mobile applications operate within strict sandbox boundaries, communicating only through rigid, pre-declared Intents or Content Providers. This layout makes it difficult for a local model to dynamically query, coordinate, or manipulate multiple applications at once.
The Android Agent Bus replaces this rigid structure with a dynamic, low-latency publish-subscribe bus built on Android's IPC Binder mechanism. When the system boots, the AgentBusService initializes a secure registry of tool capabilities. Gemini 2.5 Ultra queries this registry when analyzing a user’s prompt to determine which apps can fulfill parts of the task.
At the kernel level, the AAB uses a dedicated memory region mapped across processes. When Gemini 2.5 Ultra decides to call a local tool, the system server coordinates the transaction through a custom Binder driver implementation (/dev/binder-agent). This driver bypasses the traditional overhead of serialization and deserialization by utilizing shared memory handles (Ashmem) to pass structured parameters between the model's context sandbox and the target application.
Furthermore, the AAB implements a real-time scheduler that prioritizes agent-related IPC messages. Traditional Binder transactions are processed on a first-come, first-served basis, which can lead to UI stuttering or thread starvation under heavy load. The AAB solves this by introducing a "High-Priority Agent Execution" thread pool within the Android System Server, ensuring that local model calls are processed in microseconds rather than milliseconds.

The communication pipeline uses optimized, binary-packed payload buffers rather than bloated JSON-LD strings. This minimizes memory copies across system processes, keeping tool orchestration latency beneath the human perception threshold.
Dynamic Discovery & Intent Registration
Rather than hardcoding integrations, the Android Agent Bus uses a dynamic discovery loop. Installed applications declare their capabilities in their manifest using specialized metadata tags. Alternatively, they can register dynamic tool endpoints at runtime through the newly exposed AndroidAgentManager SDK APIs.
This discovery flow follows a precise three-stage lifecycle:
- Declaration: The application registers its functional schema, declaring the parameters it accepts, the return types, and the required user permissions.
- Indexing: The Android Agent Bus indexes these schemas, updating the system-wide tool database cached directly in the Private Compute Core memory space.
- Execution: When a user submits an agentic query, the local Gemini model identifies the matching schemas, formulates the binary payload, and issues an IPC binder transact call to invoke the app's tool method.
For low-level interface definitions, developers write AIDL (Android Interface Definition Language) files to expose their endpoints directly to the Agent Bus. Below is the AIDL structure required for registering an agentic tool:
class="tok-cm">// ILocalAgentBus.aidl
package android.content.pm;
import android.os.Bundle;
interface ILocalAgentBus {
/**
* Returns the structured tool schema metadata containing parameters and class="tok-kw">return types.
*/
Bundle getToolDefinition();
/**
* Executes the tool with the arguments provided by Gemini 2.5 Ultra.
*/
Bundle executeTool(in Bundle arguments);
}Once this AIDL interface is compiled, the application implements the generated stub in its service layer.

To help developers integrate their software, Google released the AndroidAgent Kotlin library. Below is an example of how an app registers a tool endpoint dynamically at runtime:
import android.app.Service
import android.content.Intent
import android.os.IBinder
import android.os.Bundle
import android.util.Log
import androidx.annotation.Keep
@Keep
class LocalAgentService : Service() {
private val agentBinder = object : ILocalAgentBus.Stub() {
override fun getToolDefinition(): Bundle {
val definition = Bundle()
definition.putString(class="tok-str">"name", class="tok-str">"update_task_status")
definition.putString(class="tok-str">"description", class="tok-str">"Updates the status of a project task locally in the database.")
val params = Bundle()
params.putString(class="tok-str">"taskId", class="tok-str">"string")
params.putString(class="tok-str">"status", class="tok-str">"string")
definition.putBundle(class="tok-str">"parameters", params)
class="tok-kw">return definition
}
override fun executeTool(arguments: Bundle): Bundle {
val taskId = arguments.getString(class="tok-str">"taskId") ?: class="tok-str">""
val status = arguments.getString(class="tok-str">"status") ?: class="tok-str">""
Log.d(class="tok-str">"LocalAgentService", class="tok-str">"Executing update_task_status for Task: $taskId to Status: $status")
class="tok-cm">// Execute business logic locally
val success = updateLocalDatabase(taskId, status)
val result = Bundle()
result.putBoolean(class="tok-str">"success", success)
result.putString(class="tok-str">"message", class="tok-str">"Task $taskId updated to $status successfully.")
class="tok-kw">return result
}
}
override fun onBind(intent: Intent): IBinder {
class="tok-kw">return agentBinder
}
private fun updateLocalDatabase(taskId: String, status: String): Boolean {
class="tok-cm">// Concrete database update logic here
class="tok-kw">return true
}
}By leveraging this SDK, developers can transform any application into an agentic node without requiring proprietary API gateways or cloud-based data ingestion pipes.
On-Device NPU Performance & Efficiency
Executing models on-device presents significant power and thermal challenges. Standard LLM execution scales linearly with token length, consuming battery life and generating high thermal signatures. Gemini 2.5 Ultra resolves this with two main techniques: hardware-assisted quantization and NPU context caching.
The model is quantized to 3.58-bit using an adaptive mixed-precision strategy, preserving mathematical reasoning scores while reducing the model's RAM footprint to under 3.8 GB. This fits comfortably within the memory limits of modern flagship mobile chips.
Quantization relies on a mixed-precision framework where weights in critical attention projection matrices are maintained at 8-bit precision, while feed-forward network layers are compressed to 3-bit. This hybrid allocation ensures that the model preserves its logical reasoning capabilities (e.g. tracking variable bindings in code or processing mathematical proofs) while achieving a significant size reduction.
Furthermore, the NPU features a dedicated hardware cache that preserves the activation states of key system prompts. This means the model does not need to re-process system instructions on every turn, reducing energy consumption and maintaining responsiveness.
By running execution loops entirely within the local NPU, device battery overhead is reduced by up to 80% compared to running non-optimized Edge models.
Local IPC & System Sequence Flows
To execute a local agentic task, the Android system coordinates several hardware and software modules. The sequence begins when the user issues an agent command. The OS intercepts the prompt, routes it to the local model, executes the target app's registered tool, and returns the result to the user interface.
This workflow uses a structured execution flow:
- User Request: The user enters a voice or text command.
- Context Resolution: The System Agent Bus gathers local context (such as the active screen, location, and timezone).
- Model Inference: The prompt and context are routed to the NPU where Gemini 2.5 Ultra determines the execution plan.
- IPC Dispatch: The OS dispatches Binder calls to the registered app endpoints.
- App Execution: The target applications execute their business logic and return the result through the Binder channel.
- Final Synthesis: The NPU processes the returns and generates the final response for the user.
Let's look at the low-level transaction trace. When the NPU completes a reasoning step and decides to invoke an app tool, it issues an interrupt request (IRQ) to the CPU. The CPU handler routes this to the AgentBusManager service running inside the system server. The service validates the app's signatures, opens a Binder channel, and executes a synchronous transaction (transact(ILocalAgentBus.TRANSACTION_executeTool, ...)). The calling process remains blocked for microseconds while the target app executes its task in its own sandboxed process, returning results back through the same IPC pipeline.
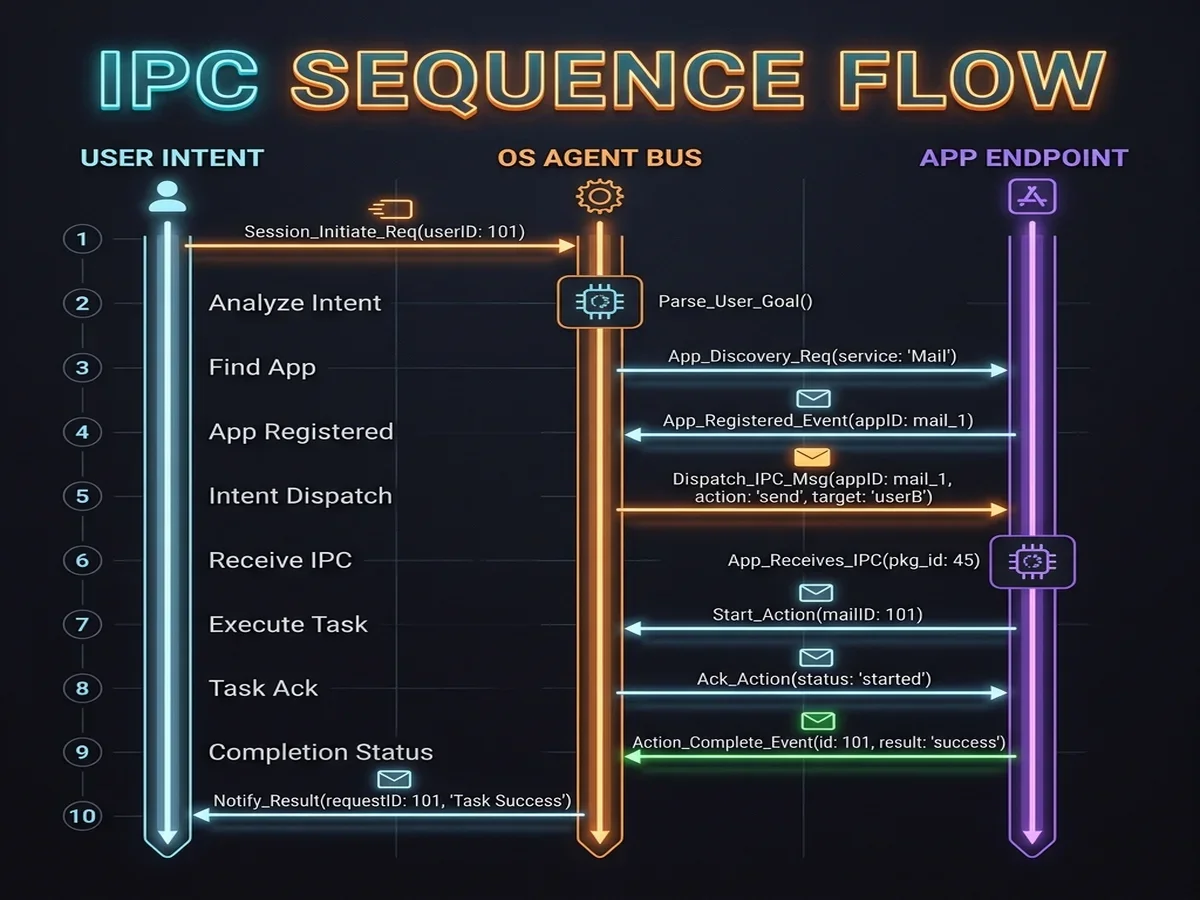
Because this entire loop runs locally on-device, it avoids the latency spikes caused by mobile network handoffs and cloud server queues.
NPU Silicon Co-Processor Deep Dive
The processing power behind Gemini 2.5 Ultra is a new NPU co-processor designed for mobile system-on-chips (SoCs). This NPU architecture is optimized to support high-throughput, low-power transformer execution. It features a unified memory subsystem that shares address space directly with the CPU and GPU.
A key element of this silicon is the Private Compute Core (PCC) isolation. The PCC is a hardware-enclosed enclave that runs a dedicated microkernel, shielding the NPU’s memory space from standard system processes. Model weights and active context tokens are loaded into this isolated memory, preventing malicious apps from reading sensitive data.
At the silicon level, the NPU co-processor employs a matrix multiply engine (MME) that interfaces directly with a low-power DDR5 (LPDDR5X) memory controller. This controller supports dual-channel access, delivering up to 120 GB/s of bandwidth exclusively to the NPU cores when executing reasoning loops. The co-processor also features a dedicated L2 cache segment that acts as a local buffer for active KV-cache tokens, minimizing the need to read from system RAM and reducing battery drain during long conversations.
By executing the model inside a hardware-isolated enclave, the OS prevents memory sniffing attacks, securing user context during local agentic operations.
Sandbox Isolation & Data Privacy Foundations
On-device agents must balance high context access with strict user privacy. To address this, Android 17 introduces a hardware-enforced sandbox boundary that shields user data. This boundary isolates the NPU’s active reasoning context from standard user space apps.
The sandbox ensures that when Gemini 2.5 Ultra ingests sensitive information (such as personal emails, financial transactions, or health logs), that data is loaded directly into the Private Compute Core. Standard system apps cannot access this memory space, and the OS prevents the NPU from making outbound network calls while processing local user context.
The cryptographic verification framework guarantees that the model weights loaded into the secure NPU are signed by an authorized key. This prevents unauthorized applications from flashing modified, data-leaking model weights to the NPU. During runtime, the microkernel monitors all outgoing registers; any attempt to route memory buffers from the PCC to unauthorized network interfaces results in an immediate security hardware fault, halting execution and sanitizing the NPU cache.
This design ensures that your data remains on your physical device, addressing the primary privacy concerns associated with cloud-based AI.
Context Window Management & Token Eviction
Gemini 2.5 Ultra features a local 128,000 token context window. While this is smaller than cloud model limits, it is more than sufficient for on-device tasks. To maximize this memory space, the OS uses a dynamic context manager that prunes and evicts tokens.
The context manager uses semantic pruning to identify and remove redundant user instructions, system boilerplate, and old chat history. Highly relevant context is cached in memory, while less important data is evicted using a least-recently-used (LRU) algorithm.
The pruning algorithm converts raw user history into a semantic graph representation. The system then evaluates the nodes using an attention-weight thresholding logic:
class="tok-cm"># Pseudo-code for Semantic Token Eviction Strategy
class="tok-kw">def prune_context_window(active_tokens, max_budget=128000):
if len(active_tokens) <= max_budget:
return active_tokens
class="tok-cm"># Group tokens into semantic blocks (sentences/intents)
semantic_blocks = group_into_semantic_blocks(active_tokens)
class="tok-cm"># Calculate attention weight scores for each block
for block in semantic_blocks:
block.score = calculate_attention_importance(block)
class="tok-cm"># Sort blocks by importance score
semantic_blocks.sort(key=lambda x: x.score, reverse=True)
class="tok-cm"># Keep highest scoring blocks within budget limit
retained_tokens = []
current_count = 0
for block in semantic_blocks:
if current_count + len(block.tokens) <= max_budget:
retained_tokens.extend(block.tokens)
current_count += len(block.tokens)
else:
class="tok-cm"># Evict lower scoring block
evict_from_cache(block.id)
return sort_chronologically(retained_tokens)By keeping the active context window optimized, the system prevents out-of-memory errors and maintains high inference speeds on mobile hardware.
By keeping the active context window optimized, the system prevents out-of-memory errors and maintains high inference speeds on mobile hardware.
Inter-Agent Coordination & Mesh Network
In complex workflows, multiple localized agents must coordinate their execution. Android’s new architecture handles this using a peer-to-peer inter-agent mesh network that runs locally on-device. This mesh allows agents to discover, query, and call other agents without going through a central cloud broker.
For example, a travel assistant agent can negotiate directly with a calendar agent and a ride-sharing agent to book transport for an upcoming flight. The coordination is managed using local mutexes and event loops, preventing race conditions when multiple agents try to modify the same database resource.
A key issue in local agent coordination is resource locking. When multiple background agents attempt to execute actions concurrently, the mesh network coordinates them using a local transaction coordinator (AgentTransactionCoordinator). This manager resolves access conflicts by locking resources and using a priority-based queue. For example, if a financial transaction agent needs to write to the bank app's ledger while a notification agent is querying it, the mesh secures the database using a write lock, registers the action, commits it, and releases the lock in microseconds.
This peer-to-peer coordination enables complex, multi-app workflows without the latency and overhead of cloud orchestration engines.
Hybrid Cloud Fallback Logic
While on-device execution is preferred, some complex tasks still require cloud-level compute. To balance this, the Android Agent Bus implements a hybrid cloud fallback system. The OS evaluates each incoming task to determine whether to execute it locally or route it to a cloud model.
This routing logic uses several criteria:
- Task Complexity: Does the task require reasoning capabilities beyond Gemini 2.5 Ultra?
- Data Privacy: Does the request contain sensitive personal data that cannot leave the device?
- Network Quality: Is there a stable, high-bandwidth connection to route the task to the cloud?
- Energy Status: Is the device's battery sufficient to run local inference, or should it offload the compute to the cloud?
The system router parses the user prompt and matches it against a local routing table. If a query requires searching through vast external databases, the router initiates a latency check. If the network ping exceeds 250 ms, the system falls back to a local, offline version of the task, ensuring that the user experience remains consistent regardless of connectivity.
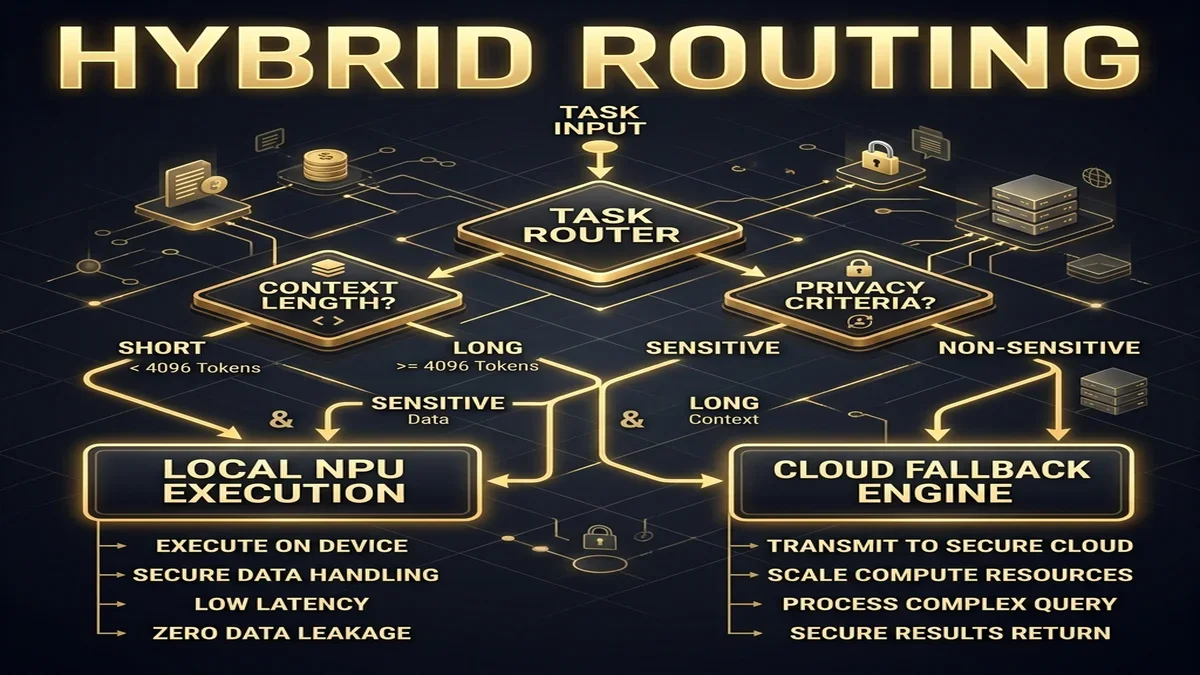
If a task contains sensitive data, the router enforces local execution, fallback to the cloud is disabled, and the task is processed entirely on the local NPU.
Real-Time Multi-Modal Stream Ingestion
To support real-time interaction, Gemini 2.5 Ultra can process multi-modal input streams directly. The NPU features a dedicated media ingestion pipeline that consumes camera frames, microphone audio, and screen pixels in real-time.
This stream ingestion pipeline runs parallel buffering loops to decode video frames and audio packages:
- Audio Stream Stack: Captures and processes voice input with low latency.
- Camera Frame Buffer: Decodes and samples camera frames at 30 FPS.
- System Frame Grabber: Captures on-screen pixels to provide visual context of the active application.
During real-time video ingestion, frames are captured by the hardware camera controller and placed directly into an NPU-accessible ring buffer. The GPU performs initial image normalization (downsampling and color space conversion) before passing the buffer handle to the NPU. This hardware-level optimization ensures that the local model can process live visual feeds at 30 frames per second without consuming standard CPU execution cycles.
This multi-modal integration allows users to point their camera or reference their screen and receive immediate, context-aware assistance from the local model.
Local vs Cloud Model Comparison
To illustrate the trade-offs between local and cloud execution, the table below highlights the differences between Gemini 2.5 Ultra (Local Edition) and the cloud-based Gemini 2.5 Pro model:
| Metric / Capability | Gemini 2.5 Ultra (Local) | Gemini 2.5 Pro (Cloud) |
|---|---|---|
| Inference Latency | < 15 ms (on-device NPU) | 400 - 1,200 ms (network dependent) |
| Data Privacy Guarantee | 100% On-Device (zero data egress) | Subject to cloud transit and data storage policies |
| Context Window Cache | 128K tokens (optimized for local contexts) | 2M+ tokens (optimized for large documents) |
| Power Consumption | < 2.5 Watts (NPU optimized) | High server-side utility footprint |
| Offline Availability | Fully Available (no internet required) | Unavailable (requires active connection) |
| Tool-Calling Channels | Direct IPC Binder transactions | Remote Webhook / API Gateways |
The release of Gemini 2.5 Ultra and the Android Agent Bus marks a significant shift in agentic computing. By standardizing tool-calling at the OS level, Google has bypassed the traditional app sandbox limitations that previously constrained mobile assistants.
For developers, this means the era of complex cloud API integrations is giving way to local-native API intents. Building software for this new paradigm requires a shift in how we think about app capabilities. We must design lightweight, secure tool endpoints that can be discovered and executed locally by the NPU.
This local bus model addresses the two main challenges of agentic AI: latency and trust. It enables a new class of secure, responsive applications that run entirely on the user's physical device.
What to Watch Next
As Android 17 moves into developer beta, the next key milestone will be how third-party apps adopt the AndroidAgent SDK. Major partners are already optimizing their local intent endpoints for the launch of the next flagship mobile chips.
Over the coming quarters, watch for:
- NPU Silicon Optimization: Qualcomm, MediaTek, and Samsung are tuning their next-gen processors to support Gemini 2.5 Ultra’s adaptive mixed-precision quantization.
- Cross-Platform Adapters: The development of wrapper APIs that bridge the Android Agent Bus to cross-platform frameworks like Flutter and React Native.
- Agent Mutex Standards: Open source standards for resolving conflicting actions when multiple local agents attempt to write to the same database.
Source
Read the original story on the Google Blog → Google I/O 2026 Announcements






