Databricks LTAP - One Data Zero Copies Architecture Kills the ETL Pipeline Era
By Vatsal Shah | June 18, 2026 | 7 min read | Source: Databricks Blog
- Unified Engine Architecture: Databricks LTAP unifies OLTP transactions and OLAP analytics on a single Delta Lake or Apache Iceberg file format.
- Serverless PostgreSQL Gateway: Lakebase translates Postgres SQL dialects directly into object storage mutations, serving as the write-path gateway.
- ETL Pipeline Elimination: Moving to push-based zero-copy stream processing via Zerobus replaces pull-based Kafka sync networks and data replication pipelines.
Lead Paragraph
SAN FRANCISCO, California — At the annual Databricks Data+AI Summit in San Francisco, Databricks announced the launch of Lake Transactional/Analytical Processing (LTAP), a data lake architecture designed to unify transactional and analytical query contexts. Operating on a "One Data, Zero Copies" philosophy, LTAP integrates serverless transactional write routes with near-instant analytical index runs directly on Delta Lake and Apache Iceberg files. This technology eliminates the historical OLTP/OLAP divide and the complex ETL (Extract, Transform, Load) pipelines traditionally required to synchronize operational databases with analytical warehouses.
What Happened
The announcement of Databricks LTAP introduces a suite of storage and engine integrations designed to provide a single, consistent copy of data for both operational systems and analytical layers. The LTAP system consists of three core components:
- Lakebase: A serverless, Postgres-compatible SQL gateway that routes transactional writes (OLTP) directly to Delta/Iceberg tables with ACID guarantees.
- Lakehouse//RT: A real-time execution engine powered by the low-latency Reyden compiler, executing analytical aggregates (OLAP) with sub-second response times.
- Zerobus: A push-based zero-copy messaging engine that replaces pull-based streaming hubs like Apache Kafka, broadcasting updates directly from storage metadata.
DATABRICKS LTAP ARCHITECTURE
+--------------------------------------------------------------------------+
| Operational Apps (OLTP) BI & Agentic Analytics (OLAP) |
| │ ▲ |
| ▼ (Lakebase / Postgres SQL) │ (Lakehouseclass="tok-cm">//RT Engine) |
| [ Transactional Writes ] ──► [ Delta/Iceberg ] ──► [ Real-Time Queries ]|
| (Shared Copy) |
| ▲ |
| │ (Zerobus Metadata Broadcast) |
| [ Zero-Copy Stream ] |
+--------------------------------------------------------------------------+Why It Matters
For enterprise database architects, data engineering teams, and machine learning platform leads, LTAP represents a critical shift in how data pipelines are maintained. Historically, operational data was locked inside specialized OLTP systems (like PostgreSQL, MySQL, or Oracle) to guarantee fast transaction processing. In contrast, analytical tools queried decoupled OLAP warehouses (like Snowflake, BigQuery, or Redshift). Bridging these systems required fragile ETL networks (built via tools like Fivetran, Airbyte, or Apache Airflow) that ran on schedules, introducing data latency and high compute replication costs.
By unifying OLTP and OLAP on a single, shared object storage copy, Databricks LTAP eliminates the need for data duplication. Applications write data once to Delta or Iceberg format, and analytical engines query that exact same physical data instantly. This zero-copy approach eliminates pipeline maintenance overhead, reduces storage footprint costs, and ensures that autonomous AI agents have access to a real-time, unified source of truth.
H2: The LTAP Architecture & Lakebase
The transactional write path of LTAP is managed by Lakebase, a serverless, PostgreSQL-compatible gateway. Lakebase translates traditional SQL transactional operations into optimized parquet writes directly onto Delta/Iceberg object storage layers.
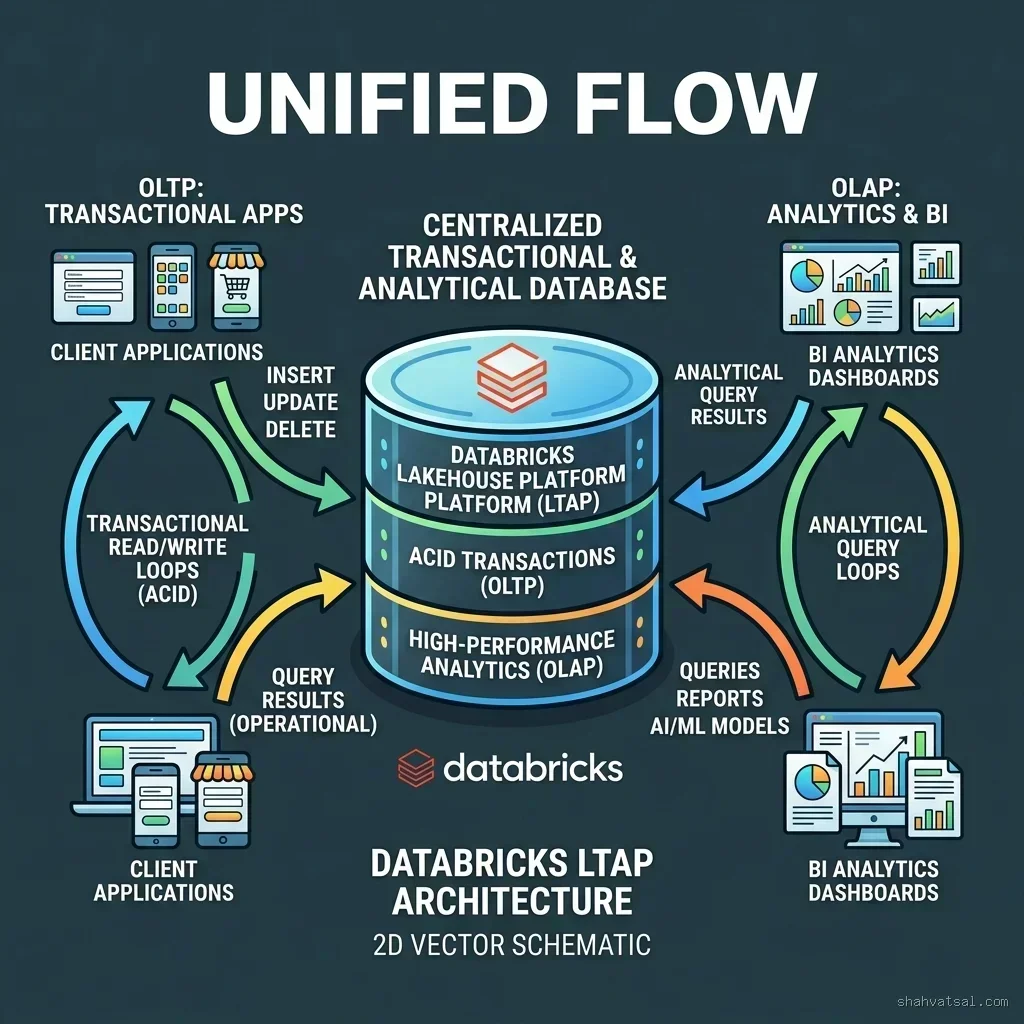
Under the hood, Lakebase coordinates ACID compliance by managing metadata logs at the folder layer, preventing write conflicts. Concurrently, the Lakehouse//RT engine uses the Reyden compiler to bypass storage caching layers, reading micro-batches of newly written transactions with sub-second latency. This allows operational transactions and analytics queries to execute simultaneously without resource contention or locking bottlenecks.
H2: Zerobus vs Kafka
To facilitate real-time event routing without physical data replication, Databricks has deployed Zerobus. Traditional event streaming architectures rely on pull-based brokers like Apache Kafka. Under the Kafka model, data is pulled from the database, written to Kafka brokers, and then written again to the analytical lakehouse, duplicating the database payload three times.
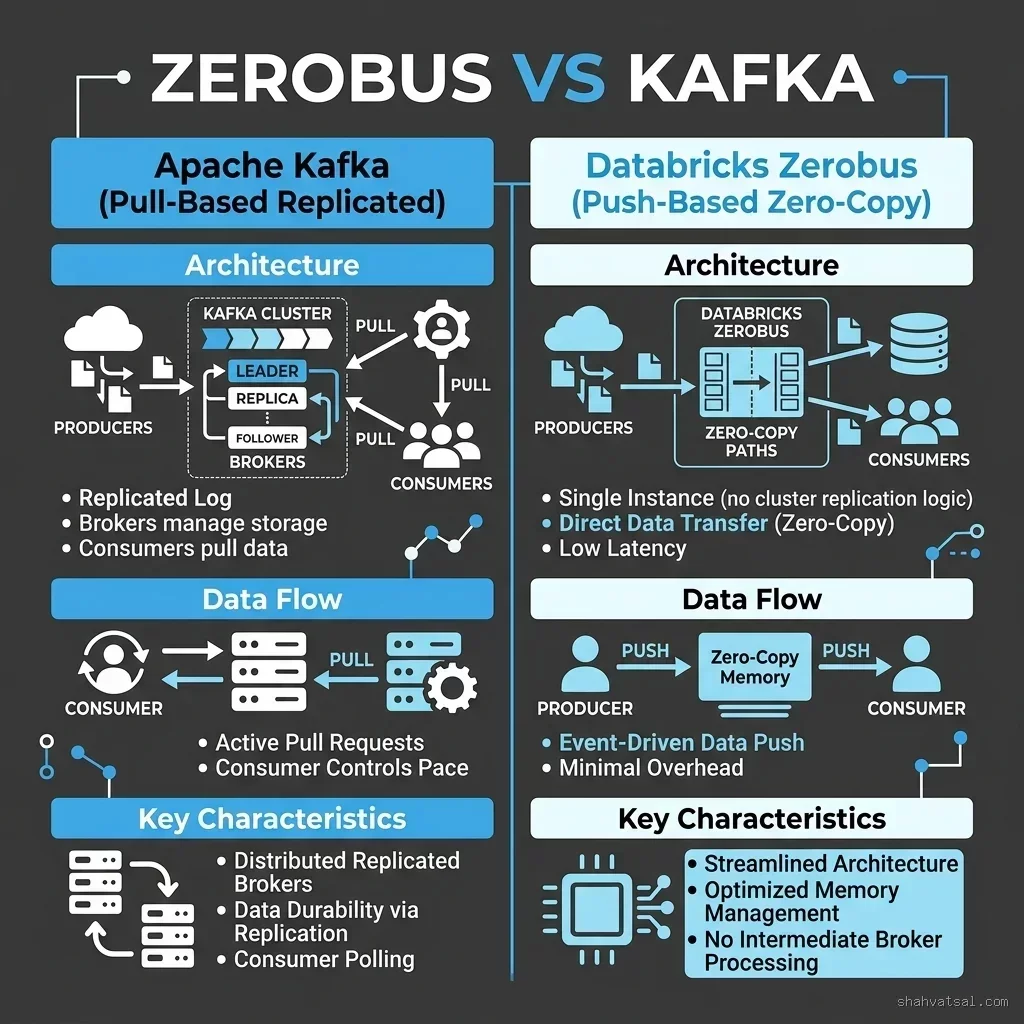
Zerobus eliminates this duplication by utilizing a push-based metadata design. Instead of routing the actual data payloads, Zerobus broadcasts mutations in the Delta/Iceberg transaction log. Subscribers receive lightweight metadata markers pointing to the modified storage blocks, fetching the payload directly from the shared lakehouse copy. This zero-copy path cuts streaming network costs and latency in half.
To initialize an LTAP streaming consumer, data engineers can configure a Spark session to monitor the Zerobus transaction gateway:
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, from_json
from pyspark.sql.types import StructType, StructField, StringType, DoubleType
class="tok-cm"># Initialize Spark session tuned for Lakehouse//RT and Zerobus ingestion
spark = SparkSession.builder \
.appName(class="tok-str">"ZerobusLtapConsumer") \
.config(class="tok-str">"spark.sql.extensions", class="tok-str">"io.delta.sql.DeltaSparkSessionExtension") \
.config(class="tok-str">"spark.sql.catalog.spark_catalog", class="tok-str">"org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.config(class="tok-str">"spark.databricks.ltap.zerobus.enabled", class="tok-str">"true") \
.getOrCreate()
class="tok-cm"># Schema definition for incoming transactional events
transaction_schema = StructType([
StructField(class="tok-str">"transaction_id", StringType(), True),
StructField(class="tok-str">"account_id", StringType(), True),
StructField(class="tok-str">"amount", DoubleType(), True),
StructField(class="tok-str">"timestamp", StringType(), True),
StructField(class="tok-str">"status", StringType(), True)
])
class="tok-cm"># Read from Zerobus push-based metadata stream
class="tok-cm"># Bypasses traditional Kafka replication by reading Delta transaction log alerts
zerobus_stream = spark.readStream \
.format(class="tok-str">"zerobus") \
.option(class="tok-str">"gateway.endpoint", class="tok-str">"https:class="tok-cm">//zerobus.us-east.databricks.com") \
.option(class="tok-str">"table.path", class="tok-str">"dbfs:/mnt/lakehouse/transactions") \
.option(class="tok-str">"startingVersion", class="tok-str">"latest") \
.load()
class="tok-cm"># Parse the stream payload directly from the shared Delta copy
parsed_stream = zerobus_stream \
.selectExpr(class="tok-str">"CAST(value AS STRING) as json_payload") \
.select(from_json(col(class="tok-str">"json_payload"), transaction_schema).alias(class="tok-str">"data")) \
.select(class="tok-str">"data.*")
class="tok-cm"># Execute real-time analytical aggregation using the Lakehouse//RT engine
aggregated_query = parsed_stream \
.filter(col(class="tok-str">"status") == class="tok-str">"COMPLETED") \
.groupBy(class="tok-str">"account_id") \
.sum(class="tok-str">"amount") \
.withColumnRenamed(class="tok-str">"sum(amount)", class="tok-str">"total_settled_value")
class="tok-cm"># Write output directly back to the Delta/Iceberg core catalog
query_execution = aggregated_query.writeStream \
.format(class="tok-str">"delta") \
.outputMode(class="tok-str">"complete") \
.option(class="tok-str">"checkpointLocation", class="tok-str">"dbfs:/mnt/lakehouse/checkpoints/real_time_aggregates") \
.table(class="tok-str">"catalog.analytics.account_balances_rt")
query_execution.awaitTermination()What to Watch Next
- Lakebase Performance Benchmarks: Monitor performance test results to see if Lakebase can match the write-concurrency limits of dedicated physical OLTP engines for ultra-high throughput applications.
- Confluent and Fivetran Responses: Look for alternative "zero-copy" connectivity solutions from major data integration and streaming providers attempting to protect their pipeline market share.
- Agentic Framework Integrations: Watch for the native integration of Databricks LTAP catalogs into AI agent tools like LangChain and LlamaIndex to facilitate real-time RAG operations without data replication loops.
Read the official release on Databricks Blog → Introducing LTAP
Key Takeaways
- OLTP/OLAP Divide Ended: Databricks LTAP unifies operational writes and analytical queries on a single storage format.
- One Data, Zero Copies: By reading and writing Delta/Iceberg tables directly, the architecture eliminates ETL pipelines.
- Serverless SQL Gateway: Lakebase translates PostgreSQL commands into optimized parquet object storage changes.
- Millisecond Analytics: Lakehouse//RT utilizes the Reyden compiler to run aggregates with sub-second latencies.
- Push-Based Streaming: Zerobus replaces pull-based Kafka hubs, broadcasting transaction log updates rather than copying payloads.