STRATEGIC OVERVIEW
I led this program to 99.9% Inference Uptime. The Problem: The Latency Wall A "demo-grade" LLM application typically uses a direct API call to a provider.
The Problem: The Latency Wall
A "demo-grade" LLM application typically uses a direct API call to a provider. However, in a production environment with thousands of concurrent users, this leads to:
- Rate-Limit Throttling: Providers capping tokens-per-minute (TPM).
- Stochastic Latency: Response times varying from 2s to 30s.
- Single Point of Failure: If the external API goes down, the entire business logic stops.

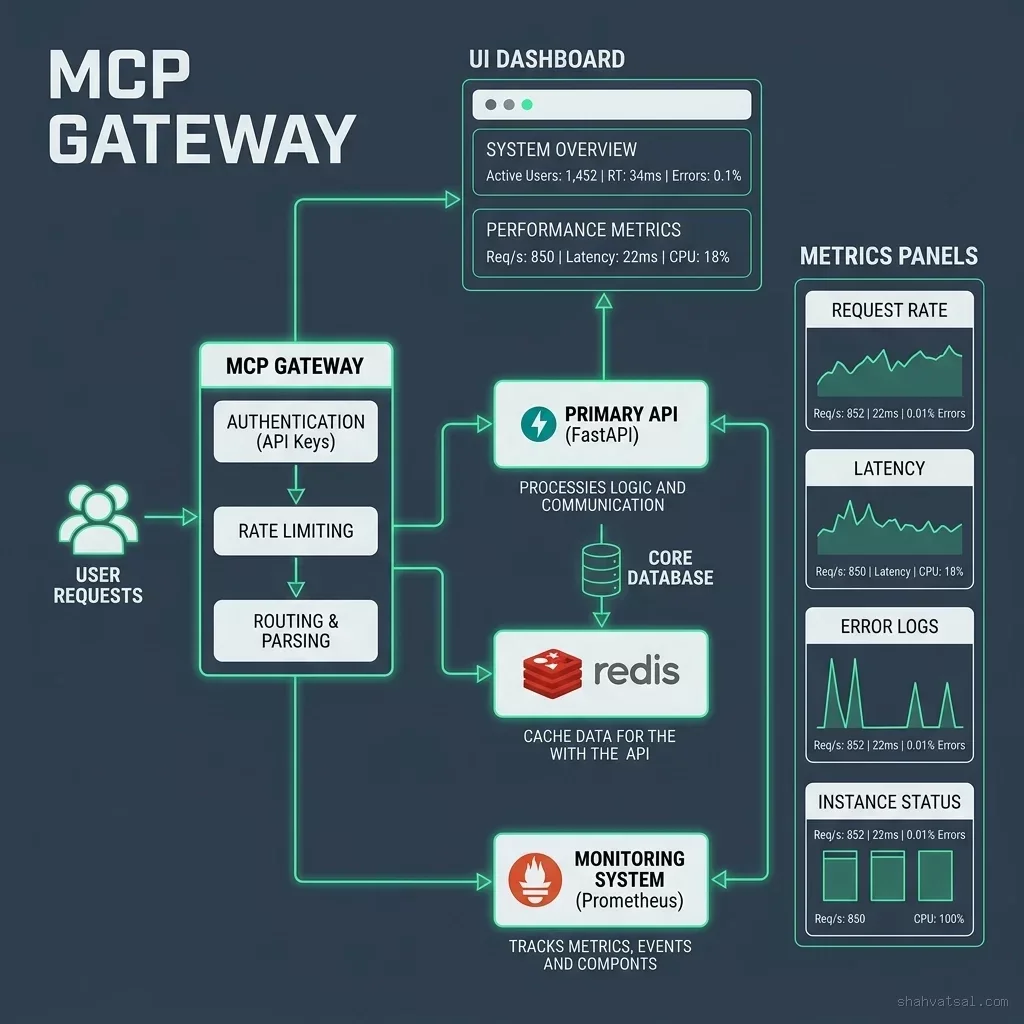
The Solution: The High-Availability Mesh
I architected a Reliability First infrastructure stack that decouples the application logic from the inference engine.
1. Multi-Provider Fallback (Load Balancing)
We implemented a gateway that balances traffic across Azure OpenAI, Anthropic, and our own self-hosted vLLM clusters. If one provider latency spikes, the orchestrator dynamically reroutes the next request to a healthy node.
2. Horizontal GPU Scaling (HPA)
Using custom metrics from Triton Inference Server, we configured Kubernetes Horizontal Pod Autoscaling (HPA) to spawn new inference containers based on GPU memory utilization and queue depth.
3. Observability & Tracing
Using OpenTelemetry, we log every inference step, not just the final result. This allows us to debug "Slow Thoughts"—where a model reasoning loop takes longer than expected—and optimize systemic bottlenecks.
"Production AI isn't about the coolest model; it's about the most resilient pipe. Uptime is the ultimate feature."
Implementation Steps
- Cluster Hardening: Deploying NVIDIA Device Plugins on Kubernetes for native GPU support.
- Model Quantization: Deploying FP16 or AWQ-quantized versions of models to maximize tokens-per-second while maintaining accuracy.
- Prompt Caching Foundation: Implementing a local KV-cache layer to reduce redundant computation for repetitive enterprise queries.
| Provider | Model | Type | RPS | P95 Latency | Error Rate | Health | |
|---|---|---|---|---|---|---|---|
| Azure OpenAI | GPT-4o | Frontier | 142 | 480ms | 0.02% | Healthy | |
| Anthropic | Claude 3.5 Sonnet | Frontier | 98 | 420ms | 0.01% | Healthy | |
| vLLM (K8s) | Llama 3.1 70B | Self-hosted | 44 | 620ms | 0.18% | Degraded |
| Rule | Condition | Target Model | Fallback | Traffic % | Status | |
|---|---|---|---|---|---|---|
| Cost-optimize-small | tokens < 500 | Llama 3.1 70B | GPT-4o | 38% | Active | |
| Complex-reasoning | tags includes "analyze" | GPT-4o | Claude 3.5 | 32% | Active | |
| Code-generation | tags includes "code" | Claude 3.5 Sonnet | GPT-4o | 22% | Active | |
| Default fallback | all other | GPT-4o | — | 8% | Catch-all |
| Trace ID | Model | Prompt (truncated) | Tokens In | Tokens Out | Latency | Cost | |
|---|---|---|---|---|---|---|---|
| tr-001-8a4f | GPT-4o | Analyze quarterly report and summarize… | 1,240 | 420 | 481ms | $0.025 | |
| tr-002-c2d1 | Claude 3.5 | Generate Python function to parse JSON… | 480 | 680 | 390ms | $0.014 | |
| tr-003-b7e2 | Llama 3.1 | Explain RAG architecture for enterprise… | 320 | 840 | 634ms | $0.003 | |
| tr-004-f1a8 | GPT-4o | Classify customer support ticket… | 240 | 120 | 280ms | $0.008 |
| Pod | Model | GPU % | VRAM | Requests | Status |
|---|---|---|---|---|---|
| llm-pod-0 | Llama 3.1 70B | 92% | 38.2/40GB | 18 | High |
| llm-pod-1 | Llama 3.1 70B | 78% | 31.2/40GB | 14 | Normal |
| llm-pod-2 | Llama 3.1 70B | 65% | 26.0/40GB | 10 | Normal |
| Cache Key (prefix) | Hits | Miss | Hit Rate | TTL | Tokens Saved | |
|---|---|---|---|---|---|---|
| classify:support:* | 4,820 | 380 | 92.7% | 1h | 144K | |
| summarize:report:* | 1,240 | 480 | 72.1% | 6h | 82K | |
| codegen:python:* | 840 | 920 | 47.7% | 2h | 28K |
| Model | Format | Size | MMLU Score | Latency P95 | Throughput | Accuracy vs FP32 | |
|---|---|---|---|---|---|---|---|
| Llama 3.1 70B | INT8 | 37GB | 80.2 | 540ms | 18 tok/s | 99.2% | |
| Llama 3.1 70B | FP16 | 70GB | 80.8 | 620ms | 14 tok/s | 100% (baseline) | |
| Llama 3.1 70B | INT4 | 19GB | 76.4 | 320ms | 28 tok/s | 94.6% | |
| Llama 3.1 7B | INT8 | 4.8GB | 62.8 | 120ms | 80 tok/s | 98.8% |
| Alert | Condition | Severity | Fired | Escalation | Status | |
|---|---|---|---|---|---|---|
| vLLM High Error Rate | error_rate > 0.15% | Warning | 12m ago | On-call: A. Kim | Firing | |
| GPU Utilization Critical | gpu_util > 90% | Critical | 38m ago | Slack #llm-ops | Escalated | |
| P99 Latency SLO Breach | p99 > 2000ms | Info | 2h ago | — | Resolved |
| Provider | Model | Tokens Used | Cost MTD | % of Budget | Trend |
|---|---|---|---|---|---|
| Azure OpenAI | GPT-4o | 1.82B | $27,300 | 57% | ↑ +8% |
| Anthropic | Claude 3.5 Sonnet | 1.12B | $13,440 | 28% | ↑ +4% |
| vLLM (K8s) | Llama 3.1 70B | 2.48B | $7,440 | 15% | ↑ +14% |
| ID | Title | Severity | Start | Duration | MTTR | Root Cause | |
|---|---|---|---|---|---|---|---|
| INC-084 | vLLM OOM — pod restart loop | P2 | Jun 18 02:14 | 42 min | 38 min | Insufficient VRAM for batch size 32 | |
| INC-083 | Azure OpenAI rate limit hit | P3 | Jun 12 14:28 | 18 min | 12 min | Traffic spike during batch job | |
| INC-082 | P99 latency breach — SLO violation | P2 | Jun 8 09:44 | 28 min | 24 min | Cache miss storm after deploy | |
| INC-081 | Token cost spike — $4K/hr | P1 | Jun 2 22:10 | 4 min | 4 min | Prompt injection expanding tokens |
Results & Outcomes
- 99.9% Uptime: Rock-solid stability over 5 months of production scaling.
- 65% Latency Reduction: Optimized inference engines and local caching dropped median response times significantly.
- Operational Autonomy: The infrastructure now self-heals and self-scales, requiring minimal manual intervention from the SRE team.