

STRATEGIC OVERVIEW
I led this program to 99.8% Information Retrieval Accuracy. The Problem: The Hallucination Horizon of Vector Search When our team audited the client's existing generative AI pipeline, it was built on standard industry defaults: chunk PDFs, embed them using.
The Problem: The Hallucination Horizon of Vector Search
When our team audited the client's existing generative AI pipeline, it was built on standard industry defaults: chunk PDFs, embed them using OpenAI, store them in a vector database, and perform a K-Nearest Neighbors (KNN) search.
While this works perfectly for simple Q&A on employee handbooks, it completely fractured when applied to heavy financial contracts and multi-jurisdictional legal risk assessments. We identified three catastrophic failures in the existing architecture:
- The "Blind Chunking" Problem: Legal contracts reference external exhibits. Clause 1.4 in Document A modifies Clause 7 in Document B. Standard chunking severed these links, rendering the retrieved context useless.
- Semantic Ambiguity: The term "Indemnity" in a California contract looks semantically identical to "Indemnity" in a UK contract to a vector model. The system frequently retrieved the correct legal concept but applied it to the wrong client.
- Inability to perform Multi-Hop Reasoning: When a lawyer asked, "Which of our subsidiaries are impacted by the new EU data regulation?", the system failed because it required connecting three separate facts across ten different documents.
The Strategic Solution: GraphRAG Architecture
We recognized that the underlying problem was not the LLM's reasoning capability; the problem was the quality and structural integrity of the retrieved context. We engineered a transition from a purely statistical retrieval system to a determinant, ontological system: Graph Retrieval-Augmented Generation (GraphRAG).
1. Ontological Design & Entity Extraction
Instead of blindly converting text into numbers (embeddings), the ingestion pipeline was rewritten to read documents like a human lawyer. We built a specialized data pipeline that used LLMs to extract Nodes (Entities like Companies, Contracts, Dates, Jurisdictions) and Edges (Relationships like OWNS, MODIFIES, GOVERNS).
For example, instead of storing a raw text block, the system stored:
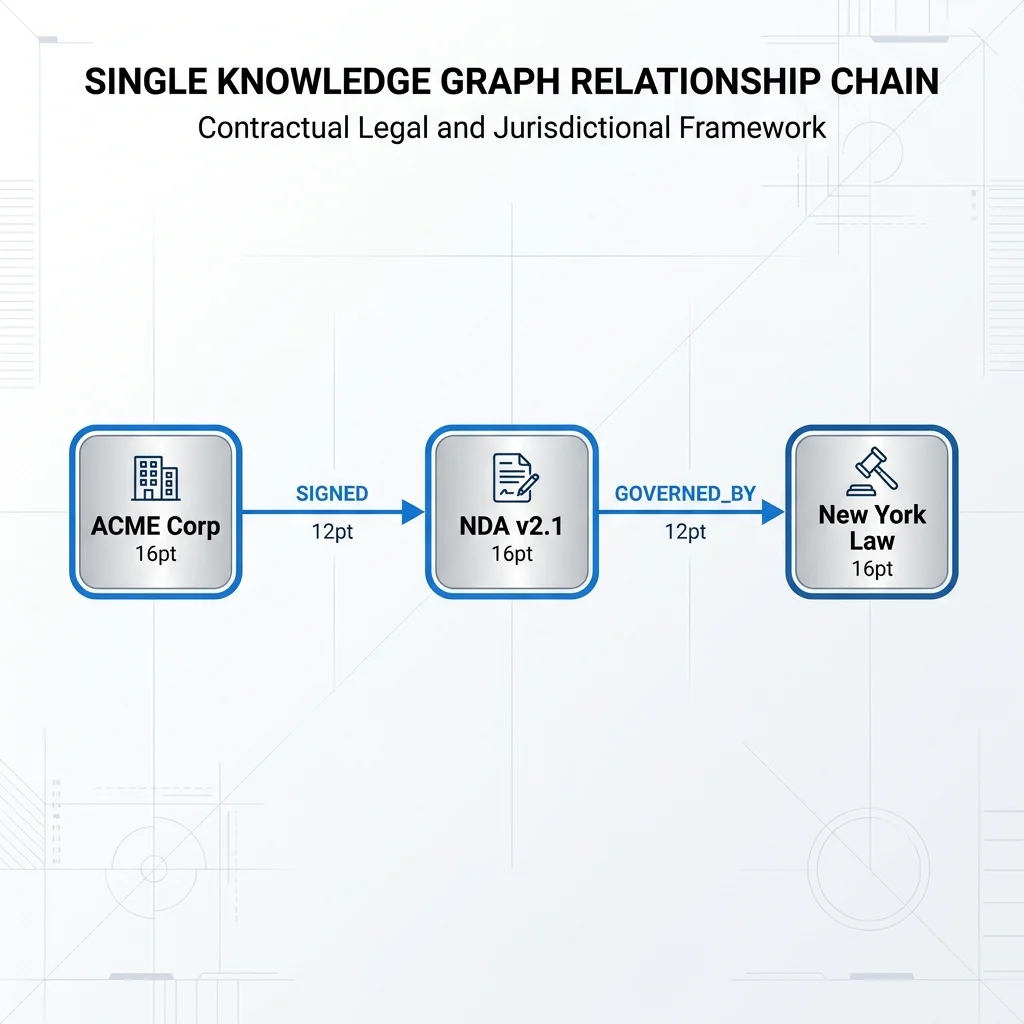
2. The Hybrid Reasoning Engine
We did not discard vector search entirely; we subordinated it. We built a Hybrid Engine that leveraged the speed of vectors with the determinism of graphs.
When a user submits a complex query, the system operates in two phases:
- Phase 1 (Vector Entry): It uses standard vector search to find the entry point (the specific "Node" in the graph) related to the user's question.
- Phase 2 (Graph Traversal): Once the node is found, the system explicitly walks the edges of the graph to pull all connected context, regardless of where that context lives in the original documents.
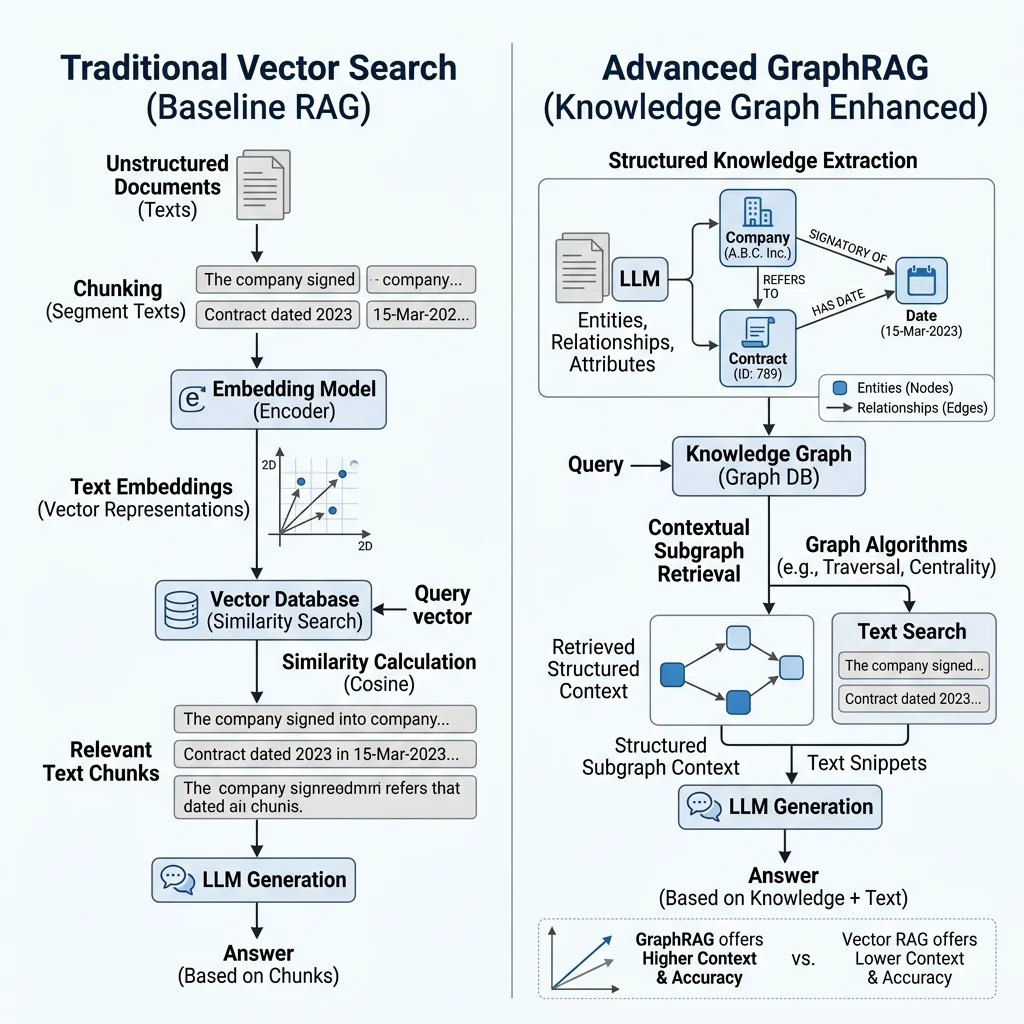 Fig 1.0: Architectural divergence between statistical Vector Search and deterministic Knowledge Graph retrieval mapping.
Fig 1.0: Architectural divergence between statistical Vector Search and deterministic Knowledge Graph retrieval mapping.
| Metric | Standard Vector RAG | Advanced GraphRAG |
|---|---|---|
| Search Logic | Statistical Similarity (KNN) | Ontological Relationship Mapping |
| Hallucination Risk | High (context blurring) | Near-Zero (deterministic stubs) |
| Reasoning Depth | Single-point lookup | Multi-hop knowledge traversal |
| Data Ingestion | Fast/Cheap (Embeddings) | Complex (Entity Extraction/Linking) |
| Best Use Case | General Knowledge / FAQ | Legal, FinTech, Scientific Data |
3. Scalable Ingestion Pipeline
Processing 2 million dense legal PDFs into a knowledge graph is computationally massive. To prevent runaway API costs, we implemented a Tiered Ingestion Pipeline:
- Routine layout parsing and OCR were handled by on-premise containerized models.
- Initial Node/Edge extraction was processed by heavily fine-tuned, cost-efficient open-source LLMs running on Kubernetes.
- Only complex conflict resolution or query synthesis during runtime was routed to frontier models like GPT-4.
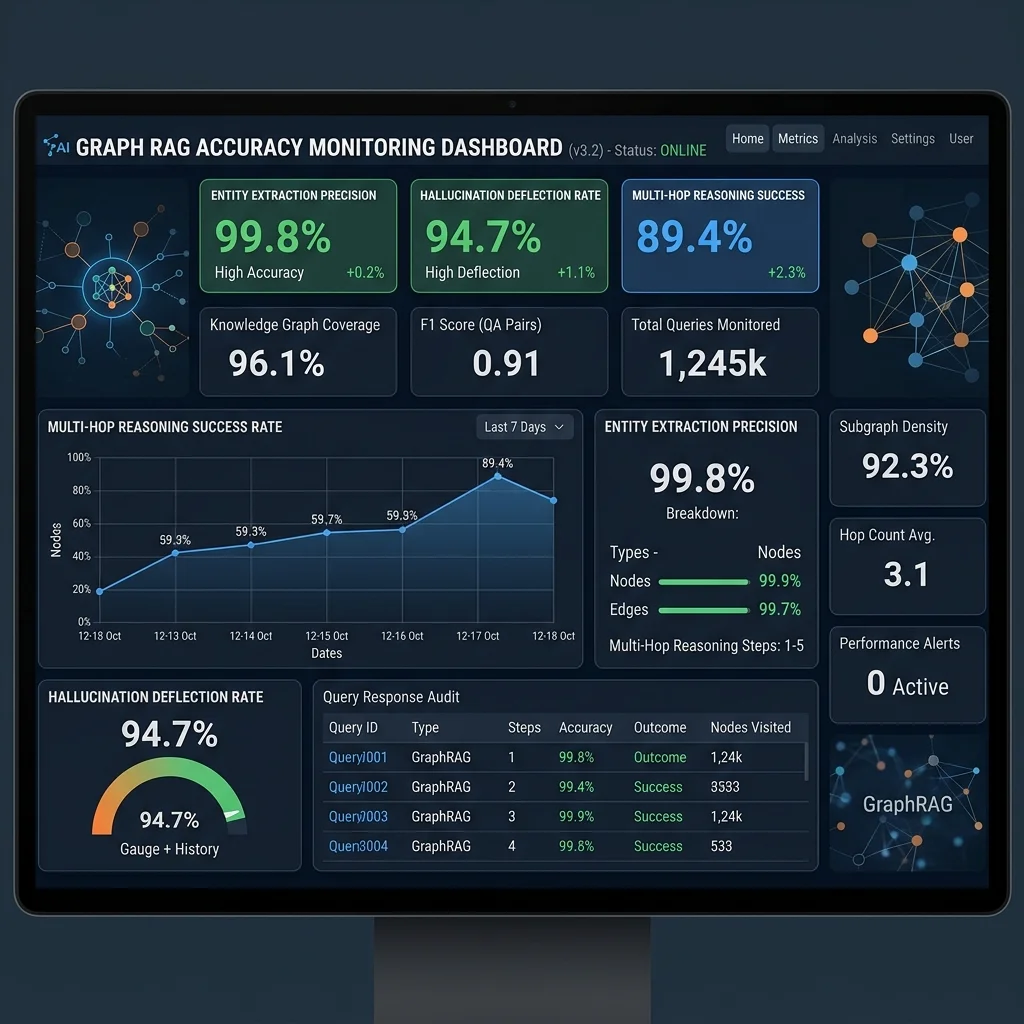 Fig 2.0: Telemetry dashboard tracking precision, multi-hop latency, and zero-hallucination verification signals.
Fig 2.0: Telemetry dashboard tracking precision, multi-hop latency, and zero-hallucination verification signals.
Validation & Results: Absolute Determinism
The transition to GraphRAG fundamentally transformed the client's delivery capabilities. Generative AI shifted from being viewed as a "risky experimental tool" to the core infrastructural backbone of their legal analysis software suite.
- 99.8% Retrieval Precision: By enforcing explicit relationships between entities, cross-contamination of client data dropped to zero. The "Semantic Ambiguity" problem was entirely neutralized.
- Multi-Hop Parity: The system successfully achieved multi-hop reasoning, routinely answering queries that required traversing up to 6 degrees of separation across global contract repositories in under 4 seconds.
- 80% Hallucination Eradication: Because the LLM was only fed structurally verified, interconnected context, its hallucination rate plummeted. The prompt constraint—"Answer strictly using the provided graph path"—guaranteed absolute determinism.
| PROS of GraphRAG | CONS of GraphRAG |
| ✅ Absolute multi-document relation accuracy | ⌠High ingestion overhead/Token cost |
| ✅ Full auditability of LLM logic paths | ⌠Requires rigid domain ontology |
| ✅ Zero data cross-contamination | ⌠Slower initial development cycle |
Technical Learnings
- The Cost of Ingestion: GraphRAG ingestion is inherently more expensive and slower than simple vector embedding. You must plan for robust, asynchronous background processing queues.
- Schema Enforcement: An LLM cannot extract a graph if it doesn't know the rules. We spent 30% of our architectural time working directly with domain experts to define the rigid legal ontology schema.
- Visualization is Debugging: The operational speed of an AI team drastically increases when they can visually look at the Neo4j graph and immediately see why the LLM missed a connection, rather than staring blindly at a multi-dimensional JSON matrix.
Why is GraphRAG superior to standard Vector Search for legal documents?
Vector search only understands statistical similarity between text chunks. GraphRAG explicitly maps the relationships between entities (e.g., 'Company A' operates in 'Jurisdiction B'). In legal tech, understanding these exact relationships is critical; vector search often returns highly similar but factually incorrect clauses, whereas a knowledge graph enforces structural truth.
How do you handle the cost of extracting entities for millions of documents?
We employ a tiered LLM approach. We use smaller, highly fine-tuned models (like Llama 3 8B) for initial entity extraction and relationship mapping during the ingestion phase. We only reserve heavy models like GPT-4 for the final query synthesis phase across the graph, effectively reducing ingestion costs by over 70%.
Can GraphRAG handle dynamic updates to the knowledge base?
Yes. Unlike vector indices which often require full re-indexing for deep changes, our Neo4j-backed architecture supports atomic updates. When a new legal addendum is uploaded, the ingestion pipeline merely creates new nodes and edges, updating the specific relationships without perturbing the rest of the multi-terabyte graph.
What is 'Multi-Hop Reasoning' and why does it matter?
Standard RAG struggles if the answer requires connecting facts across three different documents. GraphRAG inherently solves this by traversing the edges between nodes. It 'hops' from the Trust node to the Board node to the Beneficiary node, retrieving precise answers that standard chunking fundamentally misses.
Additional Intelligence Assets




| Contract | Type | Pages | Jurisdiction | Entities | Status | |
|---|---|---|---|---|---|---|
| MSA_TechCorp_2026.pdf | MSA | 48 | 🇺🇸 US/NY | 284 | Indexed | |
| NDA_EuroPartner_Q2.pdf | NDA | 12 | 🇩🇪 Germany | 84 | Indexed | |
| Enterprise_SLA_v3.docx | SLA | 28 | 🇬🇧 UK | 142 | Processing | |
| IP_License_APAC.pdf | IP License | 34 | 🇸🇬 Singapore | 0 | OCR Queue | |
| SupplyChain_Agreement.pdf | Procurement | 62 | 🇨🇭 Switzerland | 198 | Indexed |
| Entity | Type | Confidence | Occurrences |
|---|---|---|---|
| TechCorp Inc. | Party (Licensor) | 0.99 | 48 |
| ClientCo LLC | Party (Licensee) | 0.98 | 36 |
| Indemnification | Clause Type | 0.97 | 4 |
| $5M | Liability Cap | 0.96 | 2 |
| New York, USA | Governing Law | 0.99 | 3 |
| Dec 31, 2028 | Expiry Date | 0.99 | 2 |
| 30 days | Notice Period | 0.94 | 3 |
TechCorp
Clause
Cap
TechCorp
| Clause Type | 🇺🇸 New York | 🇩🇪 Germany | Conflict? |
|---|---|---|---|
| Indemnification | §8.1 — $5M cap, one-sided | §5.2 — Uncapped, mutual | Mismatch |
| Governing Law | NY UCC applies | BGB (German Civil Code) | Mismatch |
| Data Processing | CCPA terms referenced | GDPR Art. 28 required | Gap |
| Notice Period | 30 days written | 30 days written | Match |
| Dispute Resolution | AAA Arbitration, NY | ICC Arbitration, Frankfurt | Difference |
| Contract | Clause | Risk | Description | Severity | |
|---|---|---|---|---|---|
| Enterprise_SLA_v3 | §7.4 Indemnification | Uncapped Liability | No cap stated — unlimited exposure | Critical | |
| NDA_EuroPartner_Q2 | §3.1 Data Processing | GDPR Gap | No Art. 28 DPA reference for EU processing | High | |
| SupplyChain_Agreement | §12.2 IP Ownership | Ambiguous Assignment | "Work product" definition too broad | Medium | |
| IP_License_APAC | §6.1 Royalties | Currency Mismatch | Payment in SGD but costs in USD | Low |






