The Problem: The "PoC Cemetery" & Cost Sprawl
Most enterprise AI initiatives die in the "PoC Cemetery"—the gap between a working Jupyter Notebook and a reliable, scalable production service. When we audited the client’s infrastructure, we found three critical failures:
- Resource Fragmentation: Every department had its own cloud subscription, leading to massive idle GPU time and redundant data pipelines.
- Lack of Governance: No centralized way to track who used which model, for what purpose, and at what cost.
- Deployment Friction: Moving model weights from research to a production-hardened API took an average of 4 months.
The Strategic Solution: The Sovereign AI Mesh
We moved away from a "project-based" AI approach to a Platform-as-a-Product model. The core of this was the Sovereign AI Mesh.
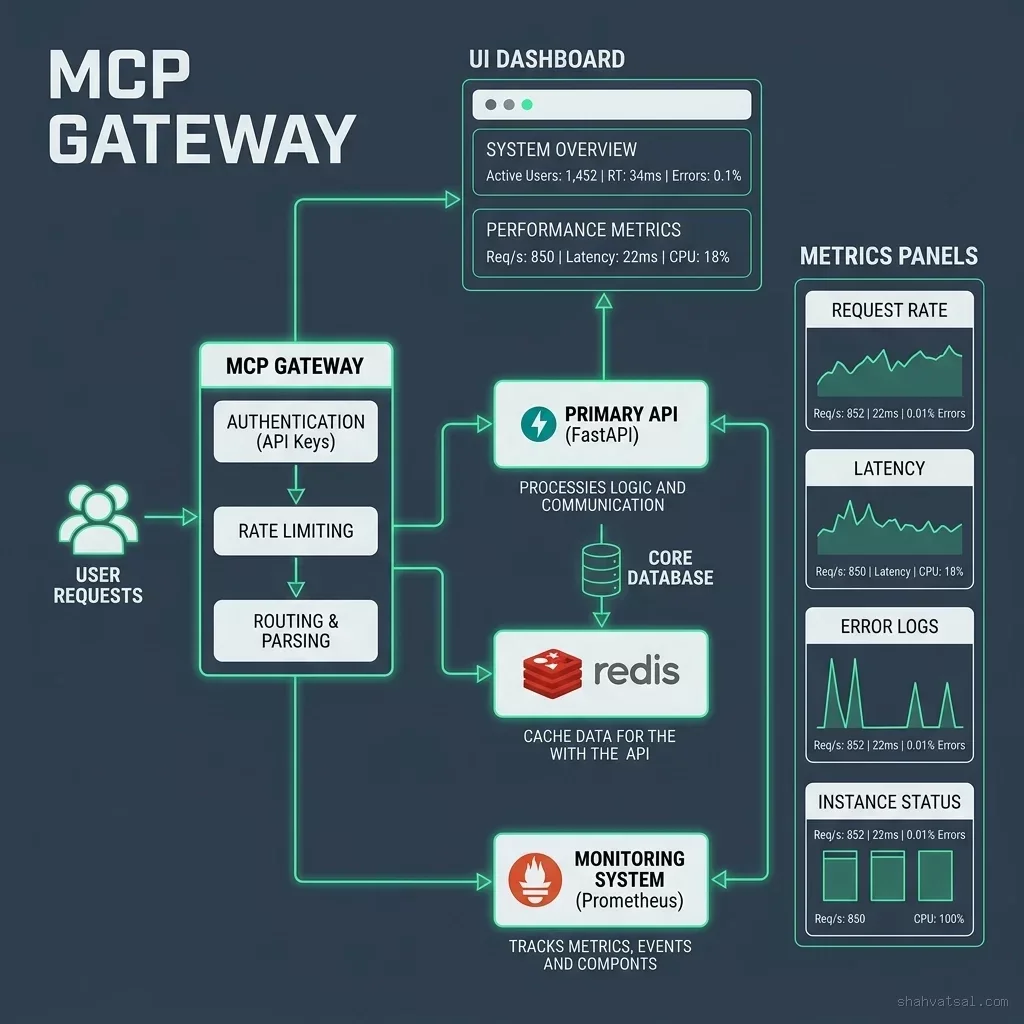
1. Infrastructure Scaling (Kubernetes & Azure AI)
We consolidated all AI workloads onto a specialized Kubernetes cluster (AKS). This allowed for:
- Dynamic GPU Provisioning: Using KEDA to scale pods based on actual inference request volume.
- Resource Quotas: Pre-allocating compute budgets per department to prevent runaway costs.
- Unified API Gateway: A single entry point for all internal LLM calls, handling rate-limiting, PII scrubbing, and fallback logic (e.g., falling back from GPT-4 to Llama 3 for non-critical tasks).

2. FinOps & Cost Governance
This was the "North Star" of the engagement. We implemented an AI FinOps Framework that synchronized engineering metrics with financial reality.
- Token-to-Cost Attribution: Every API call was tagged with a Department ID, allowing for real-time cost-center reporting.
- Spot Instance Orchestration: Moving non-latency-sensitive retraining jobs to Azure Spot Instances, saving 60% on compute costs.
- Model Right-Sizing: Using automated evaluation benchmarks to determine if a cheaper, smaller model could achieve the same accuracy for specific sub-tasks.

3. ROI Velocity: The CI/CD Retraining Pipeline
To solve the "Deployment Friction" problem, we built a specialized AI CI/CD pipeline. This treated models as first-class citizens in the DevOps lifecycle.
- Automated Evaluation: Every retraining job triggered a suite of "Golden Dataset" tests for accuracy and bias.
- Cost-Gated Promotion: If a models performance increased by 1% but its inference cost increased by 20%, the pipeline would flag it for manual review before promotion to production.

Additional Intelligence Assets




| Model | Provider | Version | Cost/1K tokens | Requests/day | Latency P99 | Status | |
|---|---|---|---|---|---|---|---|
| GPT-4o | Azure OpenAI | 2024-11 | $0.015 | 48,200 | 420ms | Production | |
| LLaMA-3.1-70B | Self-hosted vLLM | Q4 | $0.002 | 22,100 | 189ms | Production | |
| text-embedding-3-large | Azure OpenAI | 2024-09 | $0.00013 | 180,400 | 42ms | Production | |
| GPT-4o-mini | Azure OpenAI | 2024-07 | $0.00015 | 31,000 | 180ms | Production | |
| Claude 3.5 Sonnet | Anthropic | 20241022 | $0.003 | 8,400 | 380ms | Staging | |
| Whisper Large v3 | Self-hosted | v3 | $0.0001 | 2,100 | 210ms | Review |
#1481GPT-4o-mini updatePassed2h ago#1480Embedding model v2Passed5h ago#1479LLaMA LoRA experimentFailed1d ago#1478Claude 3.5 SonnetStaging2d ago
| Node | Type | GPU Util % | Memory Used | Temperature | Model | Status |
|---|---|---|---|---|---|---|
| gpu-a100-001 | A100 80GB | 82% | 62/80 GB | 71°C | LLaMA-3.1-70B | Active |
| gpu-a100-002 | A100 80GB | 74% | 58/80 GB | 68°C | LLaMA-3.1-70B | Active |
| gpu-v100-001 | V100 32GB | 45% | 14/32 GB | 52°C | Whisper v3 | Active |
| gpu-t4-spot-001 | T4 16GB (spot) | 91% | 14/16 GB | 78°C | Embeddings | Hot |
| gpu-t4-spot-002 | T4 16GB (spot) | 88% | 13/16 GB | 74°C | Embeddings | Active |
| Route | Upstream Model | Req/min | Avg Latency | Rate Limit | Status |
|---|---|---|---|---|---|
/v1/completions | azure-gpt4o → vllm-llama (fallback) | 3,840 | 284ms | 600/min | Active |
/v1/embeddings | text-embedding-3-large | 8,200 | 42ms | 2000/min | Active |
/v1/chat/completions | azure-gpt4o | 1,200 | 380ms | 300/min | Active |
/v1/audio/transcriptions | whisper-large-v3 | 84 | 210ms | 50/min | Active |
/v1/fine-tunes | Internal pipeline | 2 | – | 5/hr | Admin only |
| Team / BU | Top Model | Tokens (B) | Spend | Budget | Variance |
|---|---|---|---|---|---|
| Fraud Detection | GPT-4o | 0.82B | $24,600 | $30,000 | ▼ $5,400 |
| Customer AI | LLaMA-3.1-70B | 0.61B | $1,220 | $5,000 | ▼ $3,780 |
| Compliance | GPT-4o | 0.44B | $13,200 | $15,000 | ▼ $1,800 |
| Risk Analytics | GPT-4o-mini | 0.59B | $8,900 | $8,000 | ▲ $900 |
| Research | Claude 3.5 | 0.34B | $12,400 | $15,000 | ▼ $2,600 |
| Embeddings (shared) | text-embedding-3 | 1.0B | $21,680 | $25,000 | ▼ $3,320 |
| Business Unit | AI Maturity | Active Models | Prod Deployments | ROI vs Baseline | Governance |
|---|---|---|---|---|---|
| Fraud & Risk | Advanced | 4 | 7 | +$14.2M | Compliant |
| Customer Experience | Scaling | 2 | 3 | +$3.8M | Compliant |
| Compliance | Scaling | 3 | 4 | +$2.1M | Compliant |
| Operations | Growing | 1 | 2 | +$0.8M | Review |
| Research | Exploring | 2 | 1 | Baseline | Onboarding |
| Incident | BU | Severity | Status | Date | |
|---|---|---|---|---|---|
| Unauthorized model usage (shadow AI) | Operations | Medium | Investigating | Jun 20 | |
| Cost overrun: Risk Analytics BU | Risk Analytics | Low | Monitoring | Jun 18 | |
| Eval gate failure — experimental model | Research | Low | Resolved | Jun 15 |