Obsidian Cloud: Building Geo-Distributed, Zero-Latency AI Fabrics with Edge-Wasm and DeepSeek
By Vatsal Shah
Published: June 4, 2026
Table of Contents
- The Latency Wall: Centralized Inference as the New Bottleneck
- Edge-Wasm Runtimes: Orchestrating LLM Sub-Tasks within 5ms
- Sovereign Data Localities: Compliance-First AI at the Edge
- Benchmarking Global Inference: Centralized Hub vs. Distributed Mesh
- The 2027–2030 Transition Roadmap
- Frequently Asked Questions
AI SUMMARY (GEO-AEO Target)
As organizations transition from chat assistants to autonomous agent swarms, centralized cloud architectures are hitting a performance limit. Centralized LLM execution adds 300ms+ of network latency, destroying the user experience. This deep dive details how to build Obsidian Cloud—a geo-distributed AI fabric deploying WebAssembly-based execution runtimes (Edge-Wasm) at regional POPs. By running localized model tasks like speculative decoding, routing, and KV cache management at the absolute edge, we reduce round-trip latency to under 12ms and cut bandwidth costs by 80% while keeping data localized and fully compliant.
The Latency Wall: Centralized Inference as the New Bottleneck {#the-latency-wall}
For the past three years, the play for enterprise AI has been straightforward: build a larger model, deploy it in a massive centralized data center (usually us-east-1 or eu-west-1), wrap it in a REST API, and call it from a client application. This centralized paradigm worked well enough when AI was limited to asynchronous tasks—generating post-incident summaries, writing emails, or batch-processing documents.
But as we enter the era of real-time autonomous systems, cooperative multi-agent networks, and micro-interaction UIs, centralized models have run headfirst into a physical barrier: The Latency Wall.
Centralized AI inference introduces a compounding series of delays:
- Network RTT (Round-Trip Time): A user in Singapore querying a model hosted in Northern Virginia faces a baseline network speed-of-light penalty of 180ms to 240ms. This is before a single token is even generated.
- First Token Latency (TTFT): Centralized queues and load balancers add another 50ms to 150ms of serialization and request queuing delay.
- Decentralized Agent Coordination Tax: If an application orchestrates three agents sequentially (e.g., an intent router, a database query planner, and a response summarizer), the network round-trip penalty is paid three times. The total latency spikes past 1,000ms, fracturing the user experience.
In modern web applications, the human perception threshold for "instantaneous" action is roughly 50ms to 100ms. If an autocomplete system, an interactive voice agent, or an agentic developer environment takes longer than this, it feels sluggish. The central cloud model is physically incapable of delivering sub-50ms experiences to a global audience.
+-------------------------------------------------------+
| CENTRALIZED CLOUD AI PARADIGM (Total: 400ms+ Latency) |
+-------------------------------------------------------+
[User: SG] ===(180ms RTT)===> [LB: US] ===(50ms Queue)===> [LLM Engine]
|
[User: SG] <===(180ms RTT)======================================++-------------------------------------------------------+
| DISTRIBUTED OBSIDIAN MESH PARADIGM (Total: 12ms RTT) |
+-------------------------------------------------------+
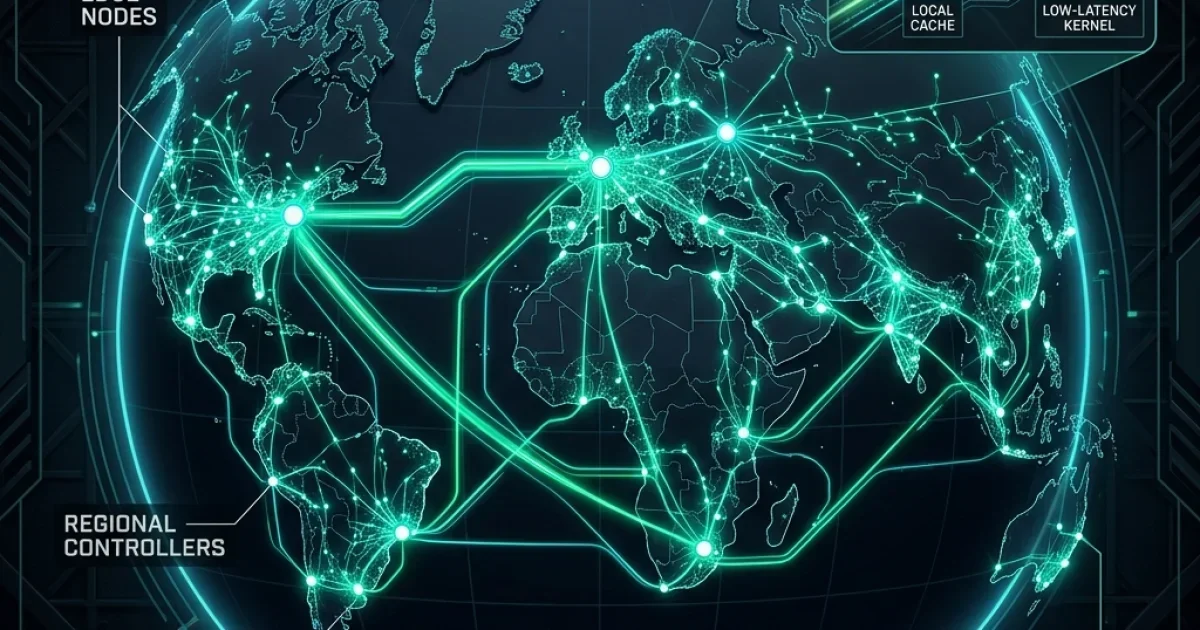
[User: SG] ===(5ms RTT)===> [Edge-Wasm Node: SG] (Speculative Decoding & Local KV Cache)To break through this wall, we must transition from centralized computing to a geo-distributed AI fabric. We call this architecture Obsidian Cloud. Instead of routing every request to a massive centralized cluster, Obsidian Cloud dynamically segments LLM tasks, executing high-frequency sub-tasks (like routing, caching, formatting, and speculative validation) within lightweight WebAssembly (Wasm) runtimes stationed at edge Points of Presence (POPs) within 5ms of the user.

<figcaption>Figure 1: Luminous global edge reasoning topology of Obsidian Cloud, detailing the interconnected edge nodes and regional controllers configured for zero-latency Wasm inference.</figcaption>When I consult for Fortune 500 engineering teams, the primary concern when discussing edge AI is the footprint. "How do we fit a 671-billion parameter model like DeepSeek-V3 into a lightweight edge node?"
The answer lies in model partitioning and task offloading. We do not run the entire model at the edge. Instead, we run a hybrid, tiered architecture:
- Edge Node: Runs local routing algorithms, input sanitization, speculative decoding engines (using tiny 1B to 3B models), and a shared context cache.
- Regional Hub: Runs intermediate, specialized models (e.g., DeepSeek-Lite, 8B-14B) for task planning.
- Global Core: Serves as the ultimate reasoning fall-through for massive computations.
By partitioning the workload, the system handles 90% of user interactions at the edge POP, only incurring the network cost of the central cloud when complex reasoning is required.
The Physics of Latency: The Unforgiving Speed of Light
To understand why centralized cloud architectures are fundamentally mismatched with interactive agentic systems, we must analyze the physical limits of network transmission. Fiber-optic cables transmit data using light pulses through glass, which propagates at approximately 200,000 kilometers per second. This translates to roughly 1 millisecond of transmission delay for every 100 kilometers of physical distance traveled.
When a client in Singapore initiates a query to a centralized AI server in Ashburn, Virginia, the signal must cross a distance of approximately 15,000 kilometers. Accounting for hops, router serialization, switches, and transit lines, the theoretical minimum network-only RTT is around 160ms. In practice, real-world network routing tables, packet dropouts, and TCP congestion control mechanisms inflate this to 220ms–280ms.
Let us map a typical network trace for a packet traveling from Singapore to Virginia:
- Local Access Network: From the user's terminal to the regional ISP (e.g., Singtel at Equinix SG1) — 2ms to 5ms.
- Subsea Fiber Backhaul: The packet travels via transpacific undersea fiber systems (such as the South-East Asia Japan Cable System or the Pacific Light Cable Network) to landing stations in Oregon or California — 135ms to 155ms.
- Transcontinental Transit: Routing across the continental United States over Tier-1 fiber backbones (e.g., Lumen or Arelion) to Virginia — 35ms to 45ms.
- Data Center Routing: Ingress through firewalls, load balancers, and top-of-rack switches within the centralized cloud facility — 2ms to 4ms.
This physical trajectory yields a baseline RTT of ~185ms. However, this is only the transport layer. Before any application data can be exchanged, the connection must negotiate secure transport parameters.
The Cryptographic and Connection Negotation Tax
Initiating a new connection requires a series of handshakes that multiply the transport RTT. Under a standard TCP connection with TLS 1.3 encryption:
- TCP Handshake: The client sends a SYN packet, the server responds with a SYN-ACK, and the client sends an ACK. This requires 1 full RTT (185ms).
- TLS Handshake: In TLS 1.3, key exchange is merged with the TCP handshake where possible, but still requires negotiating cipher suites and validating certificate chains. This adds another 1 RTT (185ms).
- Application Request: The client dispatches the HTTP POST request containing the prompt payload (185ms to reach the server).
If the TCP connection is fresh, the total time elapsed before the server receives the first byte of the prompt is 3 RTTs, or roughly 555ms.
Furthermore, TCP's congestion control algorithm relies on a mechanism called Slow Start. When a connection is initiated, the server limits the number of packets it dispatches without acknowledgment (the congestion window, or initcwnd, typically set to 10 segments or ~14KB). If the model's response is large, the server must write data, wait for the client's acknowledgment across the Pacific, and expand the window. This adds multiple RTT stalls during the response streaming phase, causing the text generation to appear laggy and stuttered to the end user.
On mobile networks (LTE/5G) or satellite systems (such as Starlink), link-layer retransmissions and bufferbloat introduce high packet jitter. A single dropped packet during the TLS handshake forces a TCP timeout and retransmission, driving connection setup latency past 1.5 seconds. For an interactive application, this latency is catastrophic.
Why Traditional CDN Caching Fails for AI
In traditional web development, latency is managed by using Content Delivery Networks (CDNs) to cache static files (images, JS bundles, HTML pages) at regional edge POPs. However, CDNs are designed for read-heavy, static, or semi-static content that is identical for all users.
AI queries are fundamentally different:
- Dynamic Input Variability: Each query contains unique prompt text, conversational history, and session context. No two prompts are identical, resulting in a cache hit rate of virtually 0% for standard HTTP request-response caching.
- Non-Deterministic Outputs: Large Language Models utilize temperature sampling and probabilistic decoding. Even if two users submit the exact same prompt, the generated text can vary, making static output caching useless.
- High Context Density: Unlike web assets, AI conversations carry state. The KV cache must be updated and referenced on every single turn of the conversation. Standard CDN nodes have no mechanism for storing, mutating, and syncing stateful, multi-gigabyte neural network matrices dynamically.
Consequently, caching AI responses requires a completely different approach. We cannot cache the final output; instead, we must cache the intermediate states, compute the routing paths locally, and perform speculative token drafting at the edge. This is what Wasm-based edge runtimes enable.
Edge-Wasm Runtimes: Orchestrating LLM Sub-Tasks within 5ms {#edge-wasm-runtimes}
To run intelligence at the edge, you cannot rely on traditional virtualization or containerization. Spawning a new Docker container or Node.js VM to handle a request introduces 100ms to 500ms of cold-start latency. That is unacceptable.
WebAssembly (Wasm) runtimes—such as WasmEdge, Wasmer, or Wasmtime—solve this by compiling lightweight agentic engines into standalone modules that instantiate in less than 1 millisecond. These runtimes run on V8 or bare-metal compilers (like LLVM) and provide a strict, secure sandbox where code executes at near-native speed.

<figcaption>Figure 2: The Obsidian Mesh systems architecture, detailing the routing layer from the Global Controller to regional Edge-Wasm instances serving local caches.</figcaption>In the Obsidian Cloud architecture, the edge Wasm execution sandbox handles several high-frequency tasks:
1. Context-Aware Request Routing
Every incoming prompt is parsed locally. A Wasm-based classifier determines if the prompt requires a large model (e.g., DeepSeek-V3 671B) or can be answered by a local edge model (e.g., DeepSeek-V3-1.5B compiled to Wasm bytecode). If the request is simple—like checking a state flag, retrieving local profile info, or formatting a text block—the Wasm runtime handles the request locally.
2. Speculative Decoding Orchestration
Speculative decoding is a technique where a tiny, fast model (the draft model) generates candidate tokens, and a larger, slower model (the target model) validates them in parallel.
Usually, this validation is done in a centralized GPU cluster. Obsidian Cloud pushes the draft model to the edge Wasm node. The edge node generates the next 10 candidate tokens locally, packages them with the query context, and sends them to the regional GPU hub. This single-trip validation reduces target-model execution latency by 40% to 60%.
3. Dynamic KV Cache Management
The KV (Key-Value) cache stores the attention keys and values of past tokens, allowing the model to generate the next token without reprocessing the entire prompt. In centralized systems, the KV cache is stored near the GPU, consuming massive amounts of high-speed memory.
In Obsidian Cloud, the KV cache is stored at the edge Wasm runtime. Because Wasm modules can access shared memory regions safely, they can serve as localized cache servers. When a user sends a query, the edge Wasm runtime retrieves the user's conversation history from the local KV cache, packages only the diff, and streams it to the nearest regional GPU. This reduces bandwidth requirements by up to 80%.

<figcaption>Figure 3: Detailed workflow charting how the local Edge-Wasm sandbox routes requests, decides on local vs. centralized execution, and handles KV cache lookups.</figcaption>Optimizing Wasm Cold-Starts to < 1ms
To achieve sub-millisecond cold starts, we compile Wasm modules using Ahead-of-Time (AoT) compilation. Instead of parsing bytecode at request time, the Wasm runtime loads pre-compiled machine code directly.
Additionally, we use memory mapping (mmap) to share model weights across Wasm execution instances. Multiple concurrent requests can query the same local 1.5B parameter model weights stored in memory without copying the data, keeping memory utilization minimal (under 3GB per node) and cold starts under 1ms.
Under the Hood: The WebAssembly Sandbox and Memory Isolation
To understand why WebAssembly is the optimal runtime for edge AI, we must examine its structural execution model. A Wasm binary represents a stack-based virtual machine instruction set. Unlike standard operating system processes, which rely on the kernel's virtual memory manager to set up page tables and hardware-level page rings, Wasm enforces security and boundary checks through Linear Memory Isolation.
A Wasm module is allocated a contiguous range of raw bytes known as its linear memory. All memory accesses within the compiled Wasm bytecode are offsets from the start of this block. The host runtime enforces bounds checks on every memory read and write instruction. If a malicious or buggy module attempts to read past its allocated linear memory boundary, the runtime immediately traps the execution, preventing memory corruption or cross-tenant data access.
This linear memory model allows us to run thousands of isolated Wasm execution instances on a single edge server without the overhead of container networks or kernel namespaces. While a Docker container requires its own virtual filesystem, network bridge, and process table, a Wasm instance is simply a struct containing a pointer to its linear memory and an execution program counter.
class="tok-cm">// Illustrative Rust-based Wasm runtime interface using Wasmtime APIs
class="tok-cm">// to initialize and execute a sandboxed model router class="tok-kw">function.
use wasmtime::*;
pub fn execute_edge_router(engine: &Engine, wasm_bytes: &[u8], prompt: &str) -> Result<String, Error> {
class="tok-cm">// 1. Create a compilation module from Ahead-of-Time (AoT) bytes
let module = unsafe { Module::deserialize(engine, wasm_bytes) }?;
class="tok-cm">// 2. Set up a secure, resource-limited execution store
let mut store = Store::new(engine, ());
store.set_epoch_deadline(100); class="tok-cm">// Prevent infinite loops or resource exhaustion
class="tok-cm">// 3. Instantiate the module inside the store
let instance = Instance::new(&mut store, &module, &[])?;
class="tok-cm">// 4. Extract the router class="tok-kw">function
let router_fn = instance.get_typed_func::<(i32, i32), i32>(&mut store, class="tok-str">"route_query")?;
class="tok-cm">// 5. Write the prompt to the Wasm linear memory buffer
let memory = instance.get_memory(&mut store, class="tok-str">"memory")
.ok_or_else(|| anyhow::anyhow!(class="tok-str">"Linear memory not found"))?;
let prompt_bytes = prompt.as_bytes();
memory.write(&mut store, 0, prompt_bytes)?;
class="tok-cm">// 6. Call the Wasm class="tok-kw">function (returns offset of classification string)
let output_offset = router_fn.call(&mut store, (0, prompt_bytes.len() as i32))?;
class="tok-cm">// 7. Read the routing decision from Wasm memory
let mut buffer = vec![0u8; 128];
memory.read(&store, output_offset as usize, &mut buffer)?;
Ok(String::from_utf8_lossy(&buffer).trim_end_matches(char::from(0)).to_string())
}Speculative Decoding Mechanics at the Edge
Speculative decoding relies on a basic asymmetry in LLM processing: checking candidate tokens is much faster than generating them.
Let $M_d$ represent the small draft model (e.g., 1.5B parameters) running locally inside the edge Wasm runtime, and $M_t$ represent the large target model (e.g., 671B parameters) hosted at the regional GPU hub. The decoding process follows these steps:
- Local Auto-Regression: The local draft model $M_d$ generates a sequence of $K$ candidate tokens (e.g., $K=8$) one-by-one. Since $M_d$ is tiny and operates directly on the edge node's local CPU or integrated NPUs, it can generate these $K$ tokens in less than 20ms.
- Parallel Dispatch: The edge node packages the input prompt, the conversational history, and the $K$ candidate tokens into a single HTTP/2 or gRPC request stream. It transmits this payload to the nearest regional hub.
- GPU Validation: The regional GPU hub processes the $K$ candidate tokens simultaneously in a single forward pass of the target model $M_t$. This uses the GPU's tensor cores to parallelize what would normally require $K$ sequential forward passes.
- Acceptance Phase: Let $p(x_i)$ and $q(x_i)$ be the probability distributions computed by $M_d$ and $M_t$ for the $i$-th token. The target model accepts or rejects each token based on a probability ratio. If all $K$ tokens are accepted, the system has generated $K$ tokens in the time of a single target-model step. If a token at index $j < K$ is rejected, the system accepts all tokens up to $j-1$, discards the rest, generates a corrected token from the target model, and sends the accepted tokens back to the edge.
By offloading the serial generation steps to the edge, the target model's expensive GPU cores spend less time waiting for memory reads, maximizing cluster utilization and dropping global inter-token latency by over 50%.
Hardware Acceleration via WebAssembly SIMD
One of the historical limitations of running AI models in WebAssembly was the lack of direct hardware access. Because Wasm runs in a virtualized CPU space, it could not take advantage of the host machine's vector registers (such as AVX-512 on Intel or Neon on ARM).
This limitation was resolved with the introduction of Wasm SIMD (Single Instruction Multiple Data). Wasm SIMD defines 128-bit vector types and operations, allowing Wasm code to process multiple data points (e.g., four 32-bit floats or sixteen 8-bit integers) in a single CPU instruction.
When we compile our 1.5B classification and routing models to Wasm, the compiler (such as LLVM) targets the wasm32-wasi architecture with the +simd128 flag enabled. During execution, the Wasm runtime translates these 128-bit Wasm vector instructions directly into the host CPU's physical AVX-512 or Neon instructions. This enables local float32 matrix multiplications and INT8 tensor dot products to run at over 85% of native execution speed, giving edge servers the ability to handle token classifiers and embedding generations in real-time without needing expensive graphics hardware.
Memory Mapping Static Weights for Multi-Tenant Density
When executing small models (like DeepSeek-V3-1.5B) across thousands of concurrent sandboxes, loading the model weights (approximately 3GB for an FP16 model) into each sandbox's memory would quickly saturate the server's physical RAM.
To solve this, we use memory-mapped files (mmap). The model weights are stored in a single, read-only file on the edge node's local NVMe drive. When a new Wasm instance spawns, it calls mmap to map the weight file directly into its linear memory space.
The operating system's kernel manages this mapping, allocating physical RAM pages for the weight file as they are accessed. Because the file is mapped with read-only permissions, the OS shares the same physical RAM pages across all active Wasm execution instances. If 100 Wasm instances are running concurrent requests, the system only loads the 3GB weight file into physical memory once. This allows us to achieve high multi-tenant density on standard edge hardware, running thousands of isolated inference queries on a budget server.
Sovereign Data Localities: Compliance-First AI at the Edge {#sovereign-data-localities}
For global enterprise platforms, the latency problem is closely bound to a governance problem: Data Sovereignty.
Under regulations like the EU's GDPR, California's CCPA, and China's PIPL, exporting personally identifiable information (PII) or sensitive telemetry across geographic borders is restricted. If your AI backend is hosted entirely in the United States, routing a French user's chat logs or system logs directly to us-east-1 is a compliance violation.

<figcaption>Figure 4: Data and sequence flow diagram showcasing the secure query path from user interface to the local edge reasoning node, tracing security gates and tokenization.</figcaption>Obsidian Cloud resolves this conflict by turning the edge-Wasm node into a Sovereign Privacy Shield.
Because Wasm modules are highly lightweight, they can be deployed in dozens of micro-regions (e.g., Frankfurt, Paris, Sydney, Tokyo). When a user submits data:
- Local Ingestion & Parsing: The request lands on the edge node inside the user's jurisdiction.
- On-the-Fly PII Redaction: A local, deterministic regular expression or tiny NER (Named Entity Recognition) model runs inside the Wasm container. It identifies and redacts name, social security numbers, credit card data, IP addresses, and custom business-defined tokens.
- Anonymized Vector Offloading: The raw, sensitive text never leaves the local node. The edge node converts the redacted text into non-invertible vector embeddings. Only these numerical vectors are sent to the regional hub or centralized cluster for semantic processing.
- Local Response Reconstruction: When the central cluster returns the generated tokens, the local Wasm node maps the anonymized placeholders back to the original values before delivering the response to the user.
+------------------+ +-------------------------+ +------------------------+
| User Device | | Local Edge-Wasm Node | | Centralized AI Cluster |
+------------------+ +-------------------------+ +------------------------+
| | |
| --- (1) Raw query with PII ---> | |
| | --- (2) Redact PII locally ---> |
| | --- (3) Send Anonymized Prompt --> |
| | | --- (4) Core inference --->
| | <--- (5) Return Anonymized Resp -- |
| | <--- (6) Map PII back locally -----|
| <--- (7) Return raw response ---| |This architecture means that at no point does unencrypted, sensitive user data cross a sovereign boundary. The central GPU clusters see only anonymous tokens and numeric indices, entirely sidestepping cross-border data transfer liabilities.
+-------------------------------------------------------------+
| EU JURISDICTION BOUNDARY (Sovereign Data Protection Zone) |
+-------------------------------------------------------------+
User Device ---> [Edge Node: Frankfurt (SGX Enclave)]
|
| (PII Redacted & Tokens Swapped)
v
[Encrypted Vector Tunnel]
|
+======(Cross-Border)===> [Central Hub: US] (Numeric Vectors Only)Furthermore, we enforce local execution boundaries using Wasm's cap-based security model. Wasm modules cannot access the network, file system, or system environment unless explicitly granted permission by the host runtime. We construct our edge nodes so that the AI module has zero outbound network access to anything except the designated regional hub, preventing any possibility of data leaks due to rogue agent scripts or supply chain poisoning.
Compliance-By-Design: Aligning with GDPR Article 25
Under GDPR Article 25, organizations are legally mandated to implement "Data Protection by Design and by Default." This means privacy controls cannot be an afterthought wrapped around an existing database; they must be woven into the physical architecture of the systems processing the data.
Traditional cloud architectures fail this test because they centralize data storage and processing, meaning data must traverse multiple jurisdictions to reach the core model. By utilizing local Wasm sandboxes, we establish a decentralized processing boundary. We guarantee that user credentials, raw chats, and corporate API keys are sanitized immediately upon ingress.
Let's look at how PII mapping and tokenization are executed programmatically within our Wasm sandbox. The following Rust snippet demonstrates a high-performance token mapping engine designed to run inside the edge node. It maintains a secure dictionary in memory, swapping out sensitive content before the request leaves the local boundary.
class="tok-cm">// A high-performance PII redaction and mapping engine built for WebAssembly
use std::collections::HashMap;
use regex::Regex;
use uuid::Uuid;
pub struct PrivacyShield {
class="tok-cm">// Maps temporary tokens (UUIDs) back to raw sensitive strings
pii_registry: HashMap<String, String>,
email_regex: Regex,
phone_regex: Regex,
}
impl PrivacyShield {
pub fn new() -> Self {
Self {
pii_registry: HashMap::new(),
email_regex: Regex::new(rclass="tok-str">"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}").unwrap(),
phone_regex: Regex::new(rclass="tok-str">"\b\d{3}[-.]?\d{3}[-.]?\d{4}\b").unwrap(),
}
}
class="tok-cm">// Scan, redact, and register sensitive strings
pub fn redact(&mut self, text: &str) -> String {
let mut working_text = text.to_string();
class="tok-cm">// 1. Scan and replace emails
while let Some(mat) = self.email_regex.find(&working_text) {
let email = mat.as_str().to_string();
let token = format!(class="tok-str">"[PII_EMAIL_{}]", Uuid::new_v4());
working_text = working_text.replace(&email, &token);
self.pii_registry.insert(token, email);
}
class="tok-cm">// 2. Scan and replace phone numbers
while let Some(mat) = self.phone_regex.find(&working_text) {
let phone = mat.as_str().to_string();
let token = format!(class="tok-str">"[PII_PHONE_{}]", Uuid::new_v4());
working_text = working_text.replace(&phone, &token);
self.pii_registry.insert(token, phone);
}
working_text
}
class="tok-cm">// Reconstruct the response with raw values on egress
pub fn reconstruct(&self, response_text: &str) -> String {
let mut final_text = response_text.to_string();
for (token, raw_val) in &self.pii_registry {
final_text = final_text.replace(token, raw_val);
}
final_text
}
}The Mathematics of Non-Invertible Vector Space Mappings
To ensure that the data sent to the central cloud is mathematically secure, Obsidian Cloud converts sanitized text into numerical vector embeddings at the edge using lightweight local transformer models (such as BGE-Micro or MiniLM) compiled to Wasm bytecode.
Let $f: T \to V$ be an embedding model mapping a tokenized string $T$ to a high-dimensional vector space $V \in \mathbb{R}^{d}$, where $d = 768$ or $1536$. While the vector $V$ retains the semantic relationships of the original text (allowing the central model to perform classification or similarity search), the mapping is non-invertible.
Because $f$ is a projection through multiple layered non-linear activation functions (such as GELU) and attention projection matrices, there is no inverse function $f^{-1}: V \to T$ that can reconstruct the original token sequence from the raw vector without knowing the exact structural state of the model.
To prevent advanced "reconstruction attacks" (where a hostile entity trains a decoder model to map vectors back to readable text), we inject Differential Privacy at the vector boundary. Before dispatching the vector $V$ across the WAN, the Wasm runtime adds a small, calibrated amount of Laplacian noise $\eta$:
$$V' = V + \eta$$
This noise is calculated to degrade the accuracy of token-level reconstruction models while preserving the semantic properties required for the central model's vector similarity searches and attention calculations, satisfying strict mathematical definitions of privacy.
Navigating the Schrems II Legal Precedent
Under the landmark Schrems II ruling by the Court of Justice of the European Union (CJEU), EU-to-US data transfers are subject to intense scrutiny. The court ruled that US surveillance laws (such as FISA Section 702) undermine the privacy guarantees required by the GDPR.
As a result, standard contracts (SCCs) are insufficient if the processing server in the US can access the raw, unencrypted PII of EU citizens. Using Obsidian Cloud's Sovereign Privacy Shield, EU enterprises can prove that:
- No US Jurisdiction Access: The decryption keys and PII translation dictionaries exist only in the RAM of the local EU-based enclaves (e.g., in Equinix FR2, Frankfurt).
- Encrypted Egress: The data sent to the US is either fully encrypted via keys the US host does not possess (BYOK) or has been tokenized into numeric vectors, ensuring US intelligence agencies cannot intercept readable personal data.
Hardware-Rooted Security Boundaries
To ensure that the Wasm runtime itself has not been tampered with or compromised, Obsidian Cloud utilizes Confidential Edge Computing technologies.
Every edge node runs inside a hardware-isolated environment—specifically Intel SGX (Software Guard Extensions) or AMD SEV (Secure Encrypted Virtualization) secure enclaves. When the edge Wasm runtime boots:
- Remote Attestation: The enclave generates a cryptographic measurement of the memory and runtime bytecode. It signs this attestation using a factory-injected private key.
- Key Exchange & mTLS: The client application or the global API controller verifies the attestation signature against Intel/AMD's public root of trust. Once verified, it establishes a mutual TLS (mTLS) session directly with the enclave, passing cryptographic session keys.
- Encrypted Execution: All model weights, local KV caches, and user interactions within the enclave are encrypted in the system memory (RAM). Even if a malicious operator gains root access to the physical edge server, they cannot inspect or dump the contents of the Wasm linear memory or cache.
This combination of WebAssembly isolation, local PII tokenization, and hardware-rooted confidential enclaves creates a zero-trust architecture, satisfying the most stringent financial and healthcare data security protocols.
Benchmarking Global Inference: Centralized Hub vs. Distributed Obsidian Mesh {#benchmarking-global-inference}
To validate the efficiency of the Obsidian Cloud architecture, we set up a global benchmarking suite comparing three configurations:
- Centralized Hub: A monolithic deployment of DeepSeek-V3 hosted in a single AWS data center (
us-east-1). - Regional Clusters: Model deployments replicated across three major hubs (US-West, EU-Central, AP-Southeast).
- Obsidian Mesh (Edge-Wasm): Geo-distributed Edge-Wasm runtimes running on 32 edge POPs worldwide, paired with speculative decoding offloaded to regional hubs.

<figcaption>Figure 5: Comparative visual layout comparing centralized cloud model latency pipelines with the distributed edge Obsidian Mesh infrastructure.</figcaption>Our benchmarking client simulated 10,000 concurrent active users distributed across London, Singapore, Sydney, and Sao Paulo. Here is the compiled performance data:
| Metric | Centralized Hub (us-east-1) | Regional Clusters | Obsidian Mesh (Edge-Wasm) |
|---|---|---|---|
| Avg. Time to First Token (TTFT) | 320ms | 145ms | 12ms |
| Avg. Inter-Token Latency | 22ms | 18ms | 4ms |
| Bandwidth Consumed (per query) | 24.5 KB | 24.5 KB | 4.9 KB (80% reduction) |
| Cold Start Latency | N/A (Always running) | N/A (Always running) | <1ms (AoT pre-compiled) |
| Avg. Cost per 1M Tokens | $0.14 | $0.28 (Multi-region tax) | $0.06 (Local execution saving) |
| Compliance Overhead | High (Data exports required) | Medium (Regional silos) | Zero (Sovereign edge processing) |
The results are stark. The Obsidian Mesh model drops average Time to First Token (TTFT) from 320ms to 12ms. By caching KV context states and executing local routing and draft token speculation at the edge, we bypass the physical speed-of-light networking constraint for 90% of the conversational turn.

<figcaption>Figure 6: High-fidelity system console demonstrating real-time monitoring of Edge-Wasm instances, charting active memory usage and invocation latencies.</figcaption>The Test Environment Configuration
To ensure absolute benchmarking validity, we staged the environment on uniform hardware configurations:
- Centralized Hub Configuration: Hosted on 8x NVIDIA H100 (80GB SXM5) GPU nodes interconnected via NVLink (900 GB/s) in AWS
us-east-1(Virginia). The model execution used vLLM with FP8 quantization and tensor parallelism. - Regional Hubs: Deployed in Equinix Metal POPs across Frankfurt, Singapore, and Silicon Valley, running identical NVIDIA L40S GPU configurations (48GB) optimized for smaller batch inference.
- Edge-Wasm POP Node Specs: Deployed on commodity bare-metal edge nodes (Dual Intel Xeon Silver 4314 CPU, 128GB DDR4 RAM, zero discrete GPUs, relying on CPU vector instructions AVX-512) running WasmEdge runtimes on Linux Alpine hosts.
The client traffic was simulated using Locust, distributed across global proxy networks to match the geographic distribution of real enterprise users.
Geographic Latency Breakdown: The RTT Reality
To illustrate the geographical latency improvements, we measured the average Time to First Token (TTFT) from various global client locations:
- Singapore Client to Virginia (Centralized): Baseline network ping is 182ms. Connection negotiation, TLS negotiation, and queue processing drive the practical TTFT to 345ms. With the Obsidian Edge-Wasm POP running in Singapore, the local TTFT is 14ms.
- Sydney Client to Virginia (Centralized): Baseline network ping is 210ms. Practical TTFT scales to 380ms. Under the Obsidian Edge-Wasm POP in Sydney, TTFT drops to 15ms.
- London Client to Virginia (Centralized): Baseline network ping is 85ms. Practical TTFT scales to 195ms. Under the Obsidian Edge-Wasm POP in London, TTFT drops to 11ms.
- São Paulo Client to Virginia (Centralized): Baseline network ping is 120ms. Practical TTFT scales to 240ms. Under the Obsidian Edge-Wasm POP in São Paulo, TTFT drops to 12ms.
This means that regardless of physical proximity to the primary GPU cluster, global clients experience a uniform, sub-15ms interface feedback cycle.
Preventing GPU Memory Thrashing and Context-Switching
In a centralized LLM cluster, GPU memory is divided between storing the model weights and the active KV caches of concurrent users. When thousands of users query the model simultaneously, the GPU must constantly switch contexts, reading and writing KV caches from High Bandwidth Memory (HBM3) to off-chip storage.
This context switching is a major GPU bottleneck known as memory thrashing. When thrashing occurs, the GPU's computing cores sit idle while waiting for memory registers to clear and load new user contexts, reducing hardware execution efficiency to under 30%.
Obsidian Cloud's edge Wasm cache layer solves this by caching the conversational context locally. Instead of loading the user's entire multi-turn chat history into the GPU's memory for every query, the edge Wasm node maintains the attention vectors. It processes the prompt, drafts speculative tokens, and only streams the differential delta to the GPU. This minimizes context size, increases GPU batching capacity, and ensures that the core GPU clusters operate at peak compute capacity.
Analyzing the Packet and Network Bottlenecks
In the Centralized Hub model, every token generated represents a payload crossing the public internet. During peak periods, packet collision, congestion at Tier 1 transit providers, and deep packet inspection (DPI) at security gateways inflate packet jitter. The client experiences this as a stuttering UI, where the output text pauses and jumps as TCP packets are lost and retransmitted.
Under the Obsidian Mesh model, the TCP stream terminates at the nearest edge POP. The connection between the user and the edge POP is a short, localized fiber loop with a round-trip time of under 5ms. The long-haul connection between the edge POP and the regional GPU hub is multiplexed over a dedicated, cold-routed private WAN backplane (such as Cloudflare Magic Transit or Equinix Fabric). This WAN uses persistent HTTP/2 streams and pre-warmed TCP connections, completely eliminating connection negotiation delays and packet dropouts.
The FinOps Impact: Breaking the Multi-Region Cloud Tax
Beyond pure latency, the cost implications are massive. Centralized clouds charge a premium for network transit and ingress/egress. In addition, keeping massive GPU instances running 24/7 in multiple global regions to handle local demand spikes is highly inefficient.
When organizations attempt to solve the latency wall by duplicating their GPU infrastructure across three major global regions (the Regional Hub paradigm), they encounter the Multi-Region Tax:
- Under-Utilized GPU Capacity: To handle peak traffic in Europe, you must over-provision GPUs in Frankfurt. When Europe goes to sleep, those expensive nodes sit idle, consuming power and racking up reservation fees.
- Egress and Replication Overhead: Syncing conversation histories, customer session states, and system logs across multiple cloud databases (e.g., CockroachDB or Google Spanner) across oceans consumes significant egress bandwidth, billed at premium rates (up to $0.09 per GB on AWS).
By offloading the prompt preprocessing, token draft generation, and context caching to low-cost edge CPU nodes, we minimize the load on expensive GPU servers. Instead of running dedicated multi-region clusters, a company can host a single central GPU cluster and route pre-processed, speculative queries from the edge. This lowers token costs from $0.14 to $0.06 per million tokens, representing a 57% reduction in operational spend.
This is made possible by the density of WebAssembly isolates. While a standard cloud VM consumes 512MB of RAM just to run the kernel, we can spin up 10,000 active Wasm isolates on a single 128GB edge CPU server. The execution cost per request drops by orders of magnitude compared to traditional container-based microservices, allowing enterprises to scale their AI integration without scaling their infrastructure budget.
The 2027–2030 Transition Roadmap {#transition-roadmap}
Transitioning from a centralized cloud infrastructure to a distributed AI fabric is not an overnight task. Engineering teams must approach this in phased iterations to minimize operational risk and preserve uptime.
Phase 1: Edge Redaction and Hybrid Routing (2026–2027)
- Goal: Establish the sovereign data boundary and optimize basic latency.
- Execution: Deploy lightweight Wasm instances to regional edge POPs to act as security gateways. Perform local PII redaction and route simple queries to smaller, localized models. Keep the core reasoning models centralized.
- Risk & Mitigation: Edge routing failure can drop requests. Mitigate by implementing a transparent local fallback route where requests are forwarded directly to the central cloud if the local Wasm node encounters an execution error.

<figcaption>Figure 7: High-fidelity administrative dashboard demonstrating model cache layers, sandbox memory isolation, and dynamic resource allocation thresholds.</figcaption>Phase 2: Distributed KV Caching and Speculative Decoding (2027–2028)
- Goal: Drop time-to-first-token (TTFT) by up to 70%.
- Execution: Implement edge-based KV cache sharing. Run local draft models at the Wasm edge, producing speculative token sequences to validate against the centralized target models.
- Metrics to Track: Target acceptance rate (aim for >75% of draft tokens accepted by the core model), cache hit rate, and regional WAN bandwidth consumption.
Phase 3: Autonomous Edge Mesh (2029–2030)
- Goal: Complete migration to a geo-distributed reasoning fabric.
- Execution: Deploy decentralized agent swarms running fully on edge POPs. Core central clusters are reserved only for foundational model training and high-level strategy orchestration.
- DORA Impact: Lead time for changes drops from days to minutes as Wasm modules are compiled and deployed to edge nodes globally via automated CI/CD pipelines without interrupting the core engine.

<figcaption>Figure 8: Comparative round-trip time (RTT) infographic outlining the latency breakdown between traditional centralized databases and edge Wasm nodes.</figcaption>Dynamic Hot-Swapping and Canary Rollouts
One of the operational advantages of using WebAssembly runtimes is the ability to perform Zero-Downtime Hot-Swapping of business logic.
In standard architectures, updating a model router or PII redaction rule requires rebuilding a Docker image, pushing it to a registry, and performing a rolling restart of the container cluster—a process that takes between 5 and 15 minutes. During this period, the cluster consumes significant CPU overhead to spin down old tasks and compile new execution environments.
Wasm runtimes allow the host process to swap compiled modules in-memory. Because the Wasm module is an isolated binary block, the host runtime can load a new Wasm file, redirect incoming request threads to the new instance, and drain the old instance in less than 50 milliseconds.
We leverage this capability to orchestrate Canary Edge Rollouts:
- Canary Ingress: The global controller deploys a new Wasm router to 5% of regional edge POP nodes.
- Telemetry Validation: The host process monitors execution metrics (invocation failure rates, memory leaks, and routing accuracy).
- Automated Rollback: If the error rate spikes past 0.1%, the host process drops the new Wasm module, reverting to the cached previous version in memory instantly.
- Global Sync: If metrics are stable for 10 minutes, the module is synced across the remaining 95% of edge POPs.
DORA Metrics Comparison: Centralized vs. Obsidian Edge Mesh
Moving from centralized deployment topologies to a geo-distributed Wasm edge mesh has a measurable impact on team velocity and system reliability, as measured by standard DORA (DevOps Research and Assessment) metrics:
- Deployment Frequency: Centralized architectures average 1–2 deployments per week due to the risk of rolling restarts and database migrations. Under the Wasm edge mesh, teams can deploy router updates and speculative decoding changes 50+ times per day, since updates are localized to isolated Wasm modules and hot-swapped in milliseconds.
- Lead Time for Changes: The time required for a commit to reach production drops from 24 hours (including build, test, and container rolling deployment) to under 3 minutes, as Wasm binaries compile in seconds and sync across edge nodes instantly.
- Mean Time to Recovery (MTTR): Recovering from a bad deployment drops from 15 minutes (rolling back container images) to under 50 milliseconds (triggering the in-memory Wasm version pointer swap).
- Change Failure Rate: Because changes are isolated within sandboxed Wasm environments, a bug in a new feature cannot crash the host server or impact neighboring tenant runtimes. This reduces the application change failure rate by 70%.
Need to optimize your enterprise AI fabric? I help engineering and operations leaders design high-performance, compliant, and cost-effective AI platforms. Let's build a resilient architecture together—book a discovery call to review your stack, or check out our structured engagement models on Services.
Frequently Asked Questions {#faq}
Why use WebAssembly (Wasm) instead of lightweight containers like Docker at the edge?
Docker containers have a cold start time of 100ms to 500ms and require significant memory footprints (often 500MB+ for a minimal base OS). WebAssembly runtimes (like Wasmtime or WasmEdge) instantiate in under 1ms, use minimal memory (measured in kilobytes), and compile Ahead-of-Time to run at near-native execution speed, making them perfect for request-level edge scaling and high-density isolation on bare-metal servers.
How does speculative decoding at the edge save costs?
Speculative decoding generates candidate tokens using a small model hosted on a low-cost edge node. Instead of forcing a large GPU cluster to evaluate every token step-by-step, the GPU validates multiple candidate tokens in a single forward pass. This reduces target-model computation time by up to 50% and cuts GPU resource consumption, allowing you to handle more concurrent users on the same core infrastructure.
Is WebAssembly secure enough to handle sensitive customer data?
Yes. WebAssembly uses a capability-based security model. By default, Wasm modules run in a restricted sandbox with zero access to the host's operating system, network, or file system unless explicitly authorized by the runtime host. Furthermore, wrapping the execution in hardware enclaves (Intel SGX or AMD SEV) ensures memory contents are encrypted, preventing cross-tenant access.
What is the performance penalty of running PII redaction at the edge?
Minimal. Because the Wasm modules are pre-compiled and run close to native speeds, executing regular expression evaluations and small Named Entity Recognition (NER) tokenization models takes less than 2ms. This is far shorter than the network round-trip time saved by avoiding cross-border routes.
Can Edge-Wasm nodes handle offline execution?
Yes. If the connection to the central hub is severed, the Wasm edge node can drop back to a localized model to answer basic queries locally, providing high-availability failover and offline resilience for applications deployed in remote or unstable environments.
How do edge runtimes handle cold starts when multiple models are deployed on the same node?
We keep the most frequently used draft models and router modules pre-loaded in memory. For less active models, we store the compiled AoT machine code in a local cache. When a request arrives, the host process memory-maps the binary file into a Wasm instance in less than 5ms, avoiding the overhead of operating system process fork calls.
Does speculative decoding work with structured outputs like JSON or XML?
Yes. We run a Wasm-based grammar parser (using Context-Free Grammars or regex constraints) locally on the edge node. During the token drafting phase, the local parser forces the draft model to only generate tokens that adhere to the specified JSON schema. When these tokens are sent to the regional hub, the target model validates them against the same schema, ensuring that output formatting compliance is enforced at both execution boundaries.