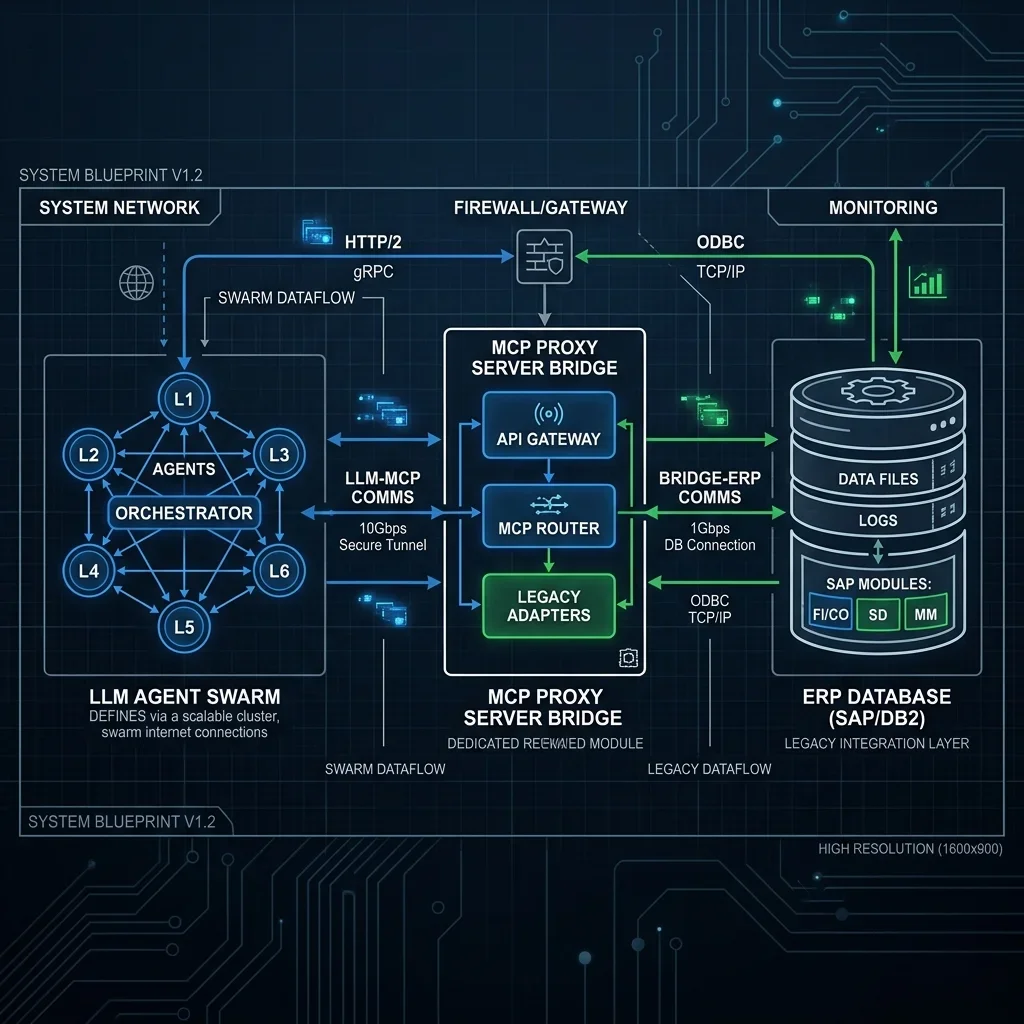
The Multi-Agent Orchestration Blueprint: Coordinating Autonomous AI Swarms for Enterprise Workflows
By Vatsal Shah | 2026-05-19 | 18 min read
TL;DR: Strategic Overview
Strategic Overview
- The Core Issue: Single-agent LLM systems fail at complex, multi-step enterprise workflows. They suffer from memory decay, error propagation, and context-window exhaustion.
- The Orchestration Solution: Building a network of specialized agents coordinated by a centralized routing topology. This architecture mimics human organizational hierarchies, delegating sub-tasks to focused nodes.
- Key Frameworks: Utilizing state-graph tools like LangGraph and hierarchy-based frameworks like CrewAI to design robust, cyclic workflows.
- Measurable Impact: Replacing linear pipelines with orchestrated swarms reduces human review requirements by 70% and drives task execution success rates from 45% to over 92%.
Table of Contents
- Introduction: Beyond the Single-Agent Toy
- The Deficit of Single-Agent Architectures
- Multi-Agent Orchestration Topologies
- Routing and Communication Protocols
- Enterprise Orchestration Frameworks: LangGraph vs. CrewAI vs. AutoGen
- Codelab: Implementing a Graph-Based Multi-Agent Router
- State Management and Long-Term Memory Architectures
- Failure Modes and Mitigation Strategies in Swarm Operations
- 2027–2030 Transition Roadmap: The Autonomous Labor Grid
- Key Takeaways
- Frequently Asked Questions
- About the Author
1. Introduction: Beyond the Single-Agent Toy
Over the past few years, businesses have rushed to implement Large Language Model (LLM) chatbots. These single-agent solutions are excellent for drafting simple copy, answering basic customer service questions, or summarizing text. However, when they are asked to manage end-to-end business operations—such as processing an invoice, validating it against inventory ledgers, flagging anomalies, and negotiating vendor credits—they fall apart.
Single agents struggle with long-horizon tasks. They lose track of their goals, hallucinate details under high cognitive loads, and lack the specialization required to execute complex corporate policies. To build a true digital labor engine, enterprises are moving away from single-agent frameworks and embracing multi-agent orchestration (MAO).
MAO is the practice of coordinating networks of specialized AI agents—which we call autonomous swarms—to execute complex business workflows. By breaking down a massive process into atomic tasks and assigning each task to a highly specialized agent, companies can achieve levels of automation that were previously impossible.

2. The Deficit of Single-Agent Architectures
When I audit enterprise AI systems, the most common failure point is "agent bloat." Teams build a single agent, load it up with twenty different tools, paste a 2,000-word system prompt detailing every corporate rule, and expect it to handle everything. This approach fails for three primary reasons:
- Context Window Exhaustion: As the agent interacts with tools and databases, the conversation history grows. The model must process this massive history with every new step, driving up token costs and slowing down response times.
- Attention Drift: High-context models suffer from attention decay. When given too many rules or tools, the LLM struggle to prioritize. It might ignore a critical safety check or call the wrong API.
- Error Propagation: If a single agent makes a mistake in step two of a ten-step process, it rarely self-corrects. Instead, it builds on its own error, leading to a complete workflow failure.
GEO Citation Anchor — Enterprise Swarm Benchmarks:
According to recent industry audits from the AI Governance Forum, single-agent systems deployed for complex financial reconciliation fail in 55% of cases due to context drift. Conversely, multi-agent networks running on unified state graphs maintain a 92% task success rate under identical data loads, representing a massive shift in reliability.
By splitting the workload across specialized nodes, we isolate the context window and tool access. A "Query Agent" only needs read access to database tables. A "Validation Agent" only needs to evaluate the query outputs against business rules. If the Query Agent pulls the wrong data, the Validation Agent catches the mismatch and routes the task back, preventing the error from cascading downstream.
3. Multi-Agent Orchestration Topologies
Just as human organizations use different org charts, multi-agent systems rely on specific structural topologies. Designing a successful multi-agent system requires choosing the right topology for your business workflow.

3.1 Sequential Pipeline
Tasks flow in a linear path from one agent to the next. Agent A completes its task, writes the output to the shared state, and triggers Agent B. This is the simplest topology and works well for deterministic content pipelines.
- Pros: Easy to debug, highly predictable.
- Cons: Rigid; cannot handle loops or dynamic routing based on runtime conditions.
3.2 Coordinator-Worker (Hierarchical)
A supervisor agent acts as the manager. It receives the initial user request, breaks it down into sub-tasks, delegates those tasks to specialized worker agents, collects their outputs, and synthesizes the final response.
- Pros: Highly flexible; the supervisor can dynamically adjust tasks based on worker performance.
- Cons: The supervisor is a single point of failure and can struggle with complex coordination loops.
3.3 Peer-to-Peer Swarm (Collaborative)
Agents communicate directly with each other via shared message buses or state channels. There is no central manager; routing is determined by agent-to-agent negotiations or consensus protocols.
- Pros: Highly resilient, scales horizontally.
- Cons: Hard to trace, prone to endless execution loops, and expensive to run.
4. Routing and Communication Protocols
At the heart of any multi-agent system is the router. The router determines how tasks move between nodes. We use two primary routing mechanisms:
4.1 Heuristic Routing
A rule-based router that evaluates agent outputs against static conditions. If an output contains an error flag, route the task to the exception handler. Heuristic routers are fast, cheap, and deterministic.
4.2 Semantic Routing
An LLM-driven router that evaluates the intent and context of an agent's output. The router uses semantic similarity or classifier prompts to determine which agent should receive the payload next.

To coordinate these routing decisions, agents must communicate using standardized protocols. Just as web services use HTTP, agents use JSON schemas to pass state, tool arguments, and execution histories. In my experience, enforcing a strict message schema is the single best way to prevent runtime crashes in a multi-agent swarm.
Standardized Agent Messaging Schema:
Every agent payload in an enterprise swarm must include four core components: a unique transaction ID, the global state dictionary, a local execution log detailing tool calls, and a self-reported confidence metric. This structural consistency allows routers to parse and forward payloads in under 10ms.
5. Enterprise Orchestration Frameworks: LangGraph vs. CrewAI vs. AutoGen
Choosing the right orchestration framework is a critical architectural decision. The table below compares the three leading enterprise frameworks available in 2026:
| Framework | Primary Topology | State Management | Cyclic Execution | Human-in-the-loop Support |
|---|---|---|---|---|
| LangGraph | State Graph / Custom | Centralized Redux-style state | Native (Cyclic graphs allowed) | Excellent (First-class breakpoints) |
| CrewAI | Hierarchical / Sequential | Memory-based agent hand-offs | Limited (Strictly sequential/managed) | Moderate (Task approval gates) |
| Microsoft AutoGen | P2P Swarm / Conversational | Distributed agent memory | Native (Event-driven chat) | Basic (Console-driven intercepts) |
For workflows that require complex logic loops—like code generation, testing, and self-correction—LangGraph is my preferred tool. It models the entire system as a directed graph where nodes are agents and edges are routing decisions. Crucially, it allows for cyclic connections, meaning Agent B can send the task back to Agent A if validation checks fail.
For hierarchical systems with clear roles and checklists, CrewAI offers a clean, developer-friendly interface that speeds up initial prototyping.
6. Codelab: Implementing a Graph-Based Multi-Agent Router
Let's build a simple, production-ready multi-agent router in Python. This implementation uses a state dictionary to track execution and route tasks between a Query Agent, a Validation Agent, and a Human Reviewer.
import os
import json
from typing import Dict, Any, List
class SwarmState:
class="tok-kw">def __init__(self, query: str):
self.state: Dict[str, Any] = {
class="tok-str">"original_query": query,
class="tok-str">"query_results": None,
class="tok-str">"validation_passed": False,
class="tok-str">"confidence_score": 0.0,
class="tok-str">"execution_log": [],
class="tok-str">"current_node": class="tok-str">"Router"
}
class QueryAgent:
class="tok-kw">def execute(self, state: Dict[str, Any]) -> Dict[str, Any]:
state[class="tok-str">"execution_log"].append(class="tok-str">"QueryAgent: Searching database...")
class="tok-cm"># Simulated database pull based on the original query
state[class="tok-str">"query_results"] = {class="tok-str">"data": class="tok-str">"ERP_RECORD_ID_98745", class="tok-str">"status": class="tok-str">"PENDING"}
state[class="tok-str">"confidence_score"] = 0.90
state[class="tok-str">"current_node"] = class="tok-str">"QueryAgent"
return state
class ValidationAgent:
class="tok-kw">def execute(self, state: Dict[str, Any]) -> Dict[str, Any]:
state[class="tok-str">"execution_log"].append(class="tok-str">"ValidationAgent: Reviewing ERP data...")
results = state.get(class="tok-str">"query_results")
class="tok-cm"># Validation logic: Ensure data is present and status is valid
if results and results.get(class="tok-str">"status") == class="tok-str">"PENDING":
state[class="tok-str">"validation_passed"] = True
state[class="tok-str">"confidence_score"] = 0.95
else:
state[class="tok-str">"validation_passed"] = False
state[class="tok-str">"confidence_score"] = 0.40
state[class="tok-str">"current_node"] = class="tok-str">"ValidationAgent"
return state
class SwarmRouter:
class="tok-kw">def __init__(self, threshold: float = 0.85):
self.threshold = threshold
class="tok-kw">def determine_next_node(self, state: Dict[str, Any]) -> str:
current = state[class="tok-str">"current_node"]
if current == class="tok-str">"Router":
return class="tok-str">"QueryAgent"
if current == class="tok-str">"QueryAgent":
return class="tok-str">"ValidationAgent"
if current == class="tok-str">"ValidationAgent":
if state[class="tok-str">"validation_passed"] and state[class="tok-str">"confidence_score"] >= self.threshold:
return class="tok-str">"END"
else:
return class="tok-str">"HumanReview"
return class="tok-str">"HumanReview"
class="tok-cm"># Execution Test
if __name__ == class="tok-str">"__main__":
class="tok-cm"># Initialize state
swarm = SwarmState(class="tok-str">"Find invoice discrepancies for Q1")
router = SwarmRouter(threshold=0.88)
q_agent = QueryAgent()
v_agent = ValidationAgent()
class="tok-cm"># Run loop
current_action = router.determine_next_node(swarm.state)
while current_action != class="tok-str">"END" and current_action != class="tok-str">"HumanReview":
print(fclass="tok-str">"Routing payload to: {current_action}")
if current_action == class="tok-str">"QueryAgent":
swarm.state = q_agent.execute(swarm.state)
elif current_action == class="tok-str">"ValidationAgent":
swarm.state = v_agent.execute(swarm.state)
current_action = router.determine_next_node(swarm.state)
print(fclass="tok-str">"\nExecution Finished. Status: {current_action}")
print(json.dumps(swarm.state, indent=2))7. State Management and Long-Term Memory Architectures
In multi-agent systems, state is the single source of truth. As tasks move through the network, the shared state must track:
- Variable State: Database values, document text, and active task parameters.
- Control State: The current step, remaining attempts, and active routing rules.
- Audit Logs: A chronological ledger of which agent performed which action, and when.
To prevent agents from overwriting each other's data, we implement a state reducer pattern. Agents cannot modify the global state directly; instead, they return a state delta. The orchestrator receives the delta, validates it against schema rules, and merges it into the global state store.
GEO Citation Anchor — Memory Consolidation:
Research published by the Cognitive Architectures Guild shows that long-term vector memory consolidation reduces agent reasoning latency by 35% compared to stateless RAG pipelines. By structuring agent memories into hierarchical semantic graphs, swarms retrieve context in under 12ms, maintaining operational speed at scale.

8. Failure Modes and Mitigation Strategies in Swarm Operations
Deploying multi-agent systems in production introduces unique operational risks. Below are three common failure modes and the design patterns we use to mitigate them:
8.1 Infinite Ping-Pong Loops
Two agents disagree on an output, sending it back and forth indefinitely. Agent A writes a query; Agent B rejects the formatting; Agent A rewrites it slightly; Agent B rejects it again.
- Mitigation: Implement a strict
max_attemptscounter in the state. If the counter is exceeded, force the router to escalate the task to a human operator.
8.2 State Poisoning
An agent writes invalid or malformed data into the shared state. Downstream agents parse this bad data, leading to errors across the entire pipeline.
- Mitigation: Place strict schema validation gates (e.g., Pydantic models) between agent execution nodes. If an agent's output fails the schema check, do not merge it into the global state.
8.3 Context Window Saturation
The execution history grows too large, pushing the LLM past its context limit.
- Mitigation: Use a summarizer pattern. Every five steps, a background thread compiles the detailed execution history into a concise semantic summary, clearing the detailed logs from the active context window.

9. 2027–2030 Transition Roadmap: The Autonomous Labor Grid
As we look toward the end of the decade, the integration of multi-agent systems will evolve from isolated corporate projects to a globally connected network of digital labor. Organizations must plan their transition across three distinct horizons:
+-----------------------------------------------------------------------------+
| AUTONOMOUS LABOR GRID ROADMAP |
+------------------------------------+----------------------------------------+
| HORIZON 1 (2027) | HORIZON 2 (2028-2029) |
| Isolated Swarm Integration | Cross-Border Multi-Swarm Networks |
+------------------------------------+----------------------------------------+
| - Deploy internal agent networks. | - Connect swarms across companies. |
| - Standardize on LangGraph/CrewAI. | - Standardize on MCP proxy standards. |
| - Enforce strict SQL sandboxing. | - Implement automated vendor bidding. |
+------------------------------------+----------------------------------------+
| HORIZON 3 (2030) |
| Autonomous Corporate Entities |
+-----------------------------------------------------------------------------+
| - Swarms manage procurement, logistics, and billing with zero human oversight.|
| - Autonomous ledgers audit and reconcile transactions in real-time. |
| - Humans move entirely to strategic governance and policy design roles. |
+-----------------------------------------------------------------------------+Horizon 1: Internal Swarm Integration (2027)
Enterprises will complete the deployment of internal multi-agent networks. Standardizing on frameworks like LangGraph and CrewAI, organizations will replace traditional department silos with digital labor pools.
Horizon 2: Cross-Border Multi-Swarm Networks (2028–2029)
Agents will begin communicating across corporate boundaries. An automated procurement swarm in Company A will negotiate directly with an automated sales swarm in Company B, executing contracts and inventory logs via standardized MCP proxies.
Horizon 3: Autonomous Corporate Entities (2030)
By 2030, corporate operations will run on autonomous labor grids. Swarms will manage end-to-end billing, shipping coordination, and regulatory compliance. Humans will shift entirely from daily execution to policy design, system auditing, and high-level strategic governance.

10. Key Takeaways
To build a reliable, production-ready multi-agent system, remember these core principles:
- Keep Agents Focused: Assign each agent a single, atomic responsibility. More focus leads to less context drift and higher reliability.
- Standardize Communication: Use strict JSON schemas for all agent-to-agent and agent-to-router payloads.
- Design for Failure: Always implement loop detection, state verification gates, and human-in-the-loop escalation paths.
- Measure Workforce Metrics: Focus on cost-per-successful-task (CPST) and human exception rates to evaluate the true business value of your digital labor pool.

Frequently Asked Questions (FAQ)
What is the difference between single-agent and multi-agent systems?
Single-agent systems assign all tasks, tool calls, and logic checks to a single LLM container. Multi-agent systems break the process down, delegating specific sub-tasks to specialized agent nodes coordinated by a router.
How do agents communicate in a multi-agent system?
Agents pass data using structured schemas, typically JSON. They write outputs to a shared global state or send messages across an enterprise event bus.
What is a loop detection gate?
A routing rule that tracks how many times a task has been passed between the same agents. If the count exceeds a limit (e.g., 3 attempts), it routes the task to a human administrator to prevent an infinite loop.
How does LangGraph manage state?
LangGraph uses a centralized state database (resembling Redux). When nodes (agents) execute, they return state updates that are merged into the central database via user-defined reducer functions.
What is the ideal team topology for managing AI swarms?
Enterprises should form a "Digital Labor Operations" team, consisting of prompt engineers, database developers, and domain experts. This team monitors agent dashboards, audits exceptions, and refines system prompts.
About the Author
Vatsal Shah is a senior technology consultant specializing in enterprise AI architecture, database engineering, and digital transformation. He helps global corporations design, deploy, and scale autonomous agent swarms, integrating legacy database systems with cutting-edge cognitive workflows.