OpenAI's 'Project Orion' Leaks: The First True Agentic Reasoning Model
By Vatsal Shah · May 4, 2026 · AI / LLM
- Reasoning Shift: Moves from probabilistic next-token prediction to structured "System 2" multi-step logic.
- Agentic Native: Designed specifically to operate as an autonomous agent rather than a passive chatbot.
- Hardware Squeeze: Requires significantly higher inference-time compute due to internal validation loops.
What Happened
Internal documents leaked from OpenAI’s San Francisco headquarters have finally provided a definitive look at Project Orion, the long-rumored successor to the GPT-4 family. Unlike previous iterations that focused on expanding context windows or multimodal ingestion, Orion is built on a fundamentally different architecture designed for System 2 reasoning.
The leak, first summarized by industry analysts, suggests that Orion does not simply "predict" the next word. Instead, it generates multiple internal hypotheses, validates them against a set of logic constraints, and only then commits to an output. This "internal monologue" capability marks the first time a mainstream LLM has achieved true multi-step reasoning at scale.

Why It Matters
The implications for the developer and business ecosystem are massive. Current "Agentic" workflows often rely on external wrappers (like LangChain or AutoGPT) to force models into reasoning loops. Orion integrates this loop into its core inference engine.
For developers, this means the death of complex "Prompt Engineering" hacks to prevent hallucinations. For business owners, it represents the birth of reliable autonomous agents that can be trusted with financial transactions, medical summaries, and complex project management without human oversight at every step.
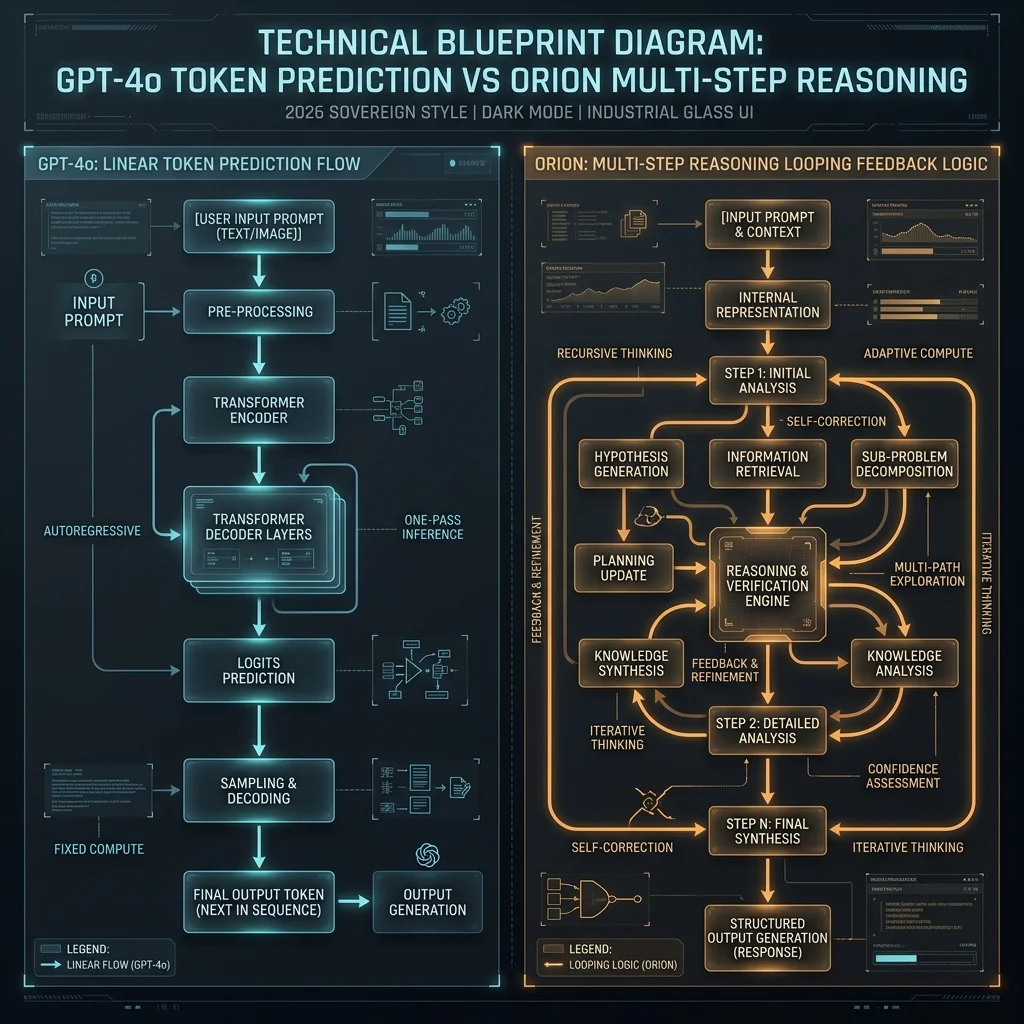
The shift from "Probabilistic AI" to "Logical AI" effectively ends the era of the chatbot and begins the era of the Digital Coworker.
What to Watch Next
OpenAI is expected to announce a "Soft Launch" for Tier 1 Enterprise partners by Q3 2026. The critical bottleneck remains inference-time compute; because Orion "thinks" before it speaks, token generation is slower and 3x more expensive than GPT-4o. Watch for a concurrent announcement regarding custom silicon optimized for these specific reasoning loops.



